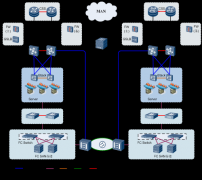
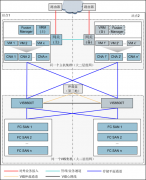
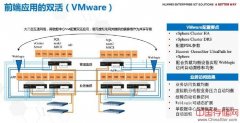
华为存储双活解决方案结合Oracle RAC、VMware、FusionSphere等应用系统提供最高级别的业务连续性保障,确保业务系统发生设备故障、甚至单数据中心故障时,业务无感知并自动切换,实现RPO(Recovery Point Objective)=0,RTO(Recovery Time Objective)≈0(RTO视应用
华为存储双活解决方案技术白皮书V3.1 目 录
|
3.1 华为OceanStor 18000系列产品... 27 |
前 言
华为存储双活解决方案技术白皮书V3.1技术白皮书主要描述华为存储双活解决方案在Oracle RAC、VMware和FusionSphere场景下的应用,提供经过验证的系统架构建议
本白皮书针对以下读者:(本文版权内容为华为所有)
- 华为市场一线的销售人员、华为客户培训人员、华为售后服务人员
- 客户技术决策人员,企业架构师
- 客户系统管理员
1 概述
1.1 数据中心业务连续性的挑战
随着信息化技术的飞速发展,信息系统在各种行业的关键业务中扮演着越来越重要的角色。在通讯、金融、医疗、电子商务、物流、政府等领域,信息系统业务中断会导致巨大经济损失、影响品牌形象并可能导致重要数据丢失。因此,保证业务连续性是信息系统建设的关键。
当前各行业普遍通过建设灾备中心来保证关键应用的业务连续性。传统灾备部署方式为一个生产中心、一个灾备中心,灾备中心平台处在不工作状态,只有当灾难发生时,生产数据中心瘫痪,灾备中心才启动。这种灾备系统面临以下挑战:
l 当生产中心遭遇供电故障、火灾、洪灾、地震等灾难时,需要手动将业务切换到灾备中心,业务中断时间长,无法保证业务连续运行。
l 灾备中心不能对外提供服务,常年处于闲置状态,资源利用率低。
针对传统灾备系统建设面临的挑战,基于华为存储的双活解决方案应运而生。
1.2 方案概述
华为存储双活解决方案指两个数据中心都处于运行状态,可以同时承担相同业务,提高数据中心的整体服务能力和系统资源利用率。两个数据中心互为备份,当单数据中心故障时,业务能自动切换到另一数据中心,业务不中断。
华为提出以虚拟化智能存储和智能光传送平台为基础的存储双活架构,并与Oracle RAC结合,为客户提供100km内的华为存储双活解决方案,解决了传统灾备中心不能承载业务和业务无法自动切换的问题。
华为存储双活解决方案结合Oracle RAC、VMware、FusionSphere等应用系统提供最高级别的业务连续性保障,确保业务系统发生设备故障、甚至单数据中心故障时,业务无感知并自动切换,实现RPO(Recovery Point Objective)=0,RTO(Recovery Time Objective)≈0(RTO视应用系统而定)。
华为存储双活解决方案拥有专业的双活容灾管理软件,运维管理进入可视化年代,支持可视化展示双活物理拓扑,并能监控各网元(主机、虚拟化网关、磁盘阵列)的状态;支持可视化展示双活逻辑拓扑,呈现应用-虚拟化网关-存储的端到端映射关系和数据流向;
通过实际验证,该方案满足系统高可用、数据高可靠、业务高连续性等需求。
1.3 方案亮点
华为存储双活解决方案的亮点和优势如下:
Active-Active的存储双活平台
主机集群可通过两边存储同时访问同一个虚拟卷,上层主机集群可跨站点部署在两个数据中心。任何数据中心存储故障,存活数据中心自动接管业务。
支持快照,防止逻辑错误导致数据丢失
虚拟化网关自带快照功能,保障人为误操作、病毒攻击以及逻辑错误导致数据损坏时,可快速实现数据回滚,提高数据可靠性。
双活业务和拓扑可视化管理
支持对两个数据中心设备的统一管理和监控,简化设备维护;
1.4 主要内容
白皮书涵盖了以下主题:
l 介绍华为存储双活解决方案的设计架构,描述虚拟化智能存储(以下简称VIS)共享卷、VIS镜像、长距离光传输网络、Oracle RAC、VMware集群、FusionSphere集群等技术,说明基于以上技术100km内存储双活解决方案的具体实现。
l 介绍方案中各关键组件的基本原理及配置。
l 介绍方案可靠性验证及性能验证结果。
2 方案架构
2.1 架构图
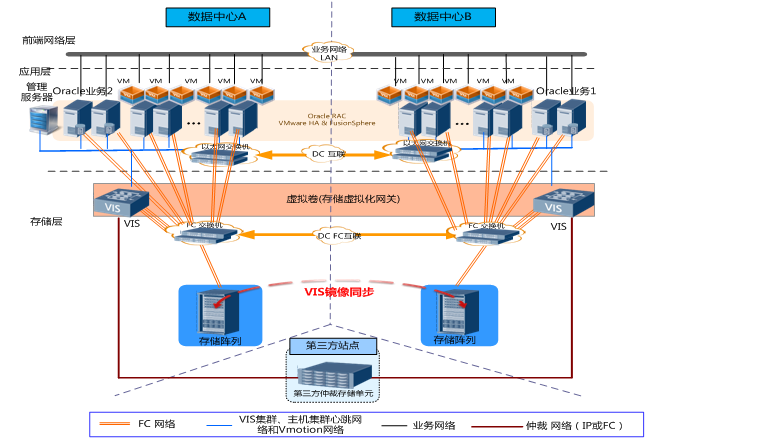
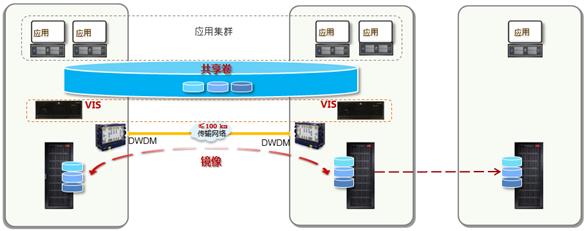
方案架构如上图所示,两个数据中心的VIS组成跨站点双活集群,利用VIS镜像卷技术,实现两中心数据的互备保护。利用VIS共享卷技术,为上层应用提供跨数据中心访问的共享数据卷,实现Oracle RAC集群或VMware集群跨站点部署。并采用密集波分复用(DWDM)设备,实现心跳、FC SAN业务的汇聚和100km长距离数据传输。两个数据中心相距小于25km时,可采用单模光纤直连两个站点,实现近距离拉远。
两个数据中心分别部署多台服务器、1或2台VIS、多台存储阵列、至少2台可提供10GE与GE链路的冗余以太网交换机以及2台光纤交换机。其中服务器组成多节点的Oracle RAC集群,VMware集群或FusionShere集群,对外提供服务; VIS组成4节点或8节点的VIS集群,统一接管 2个数据中心的磁盘阵列,构建跨站点的存储资源池;两个数据中心之间利用VIS镜像功能同步数据。
第三方仲裁站点使用第三方仲裁存储单元,使用IP或FC网络连接到双活数据中心的VIS设备。每个数据中心的一台阵列和第三方仲裁存储单元各提供一个1GB的 LUN,共3块仲裁盘,供VIS仲裁使用。
2.2 存储设计
2.2.1 同城跨中心数据保护
跨中心镜像
存储双活解决方案必须保证任一数据中心发生灾难时,另一中心有相同数据可供访问。方案利用VIS镜像卷技术,保证两个数据中心存储阵列之间数据的实时同步。由于VIS镜像卷技术对主机层透明,当任一存储阵列故障时,镜像阵列无缝接管业务,数据零丢失,业务零中断。VIS镜像卷配置对象关系图如下所示。
图2-2 VIS镜像卷逻辑对象关系图
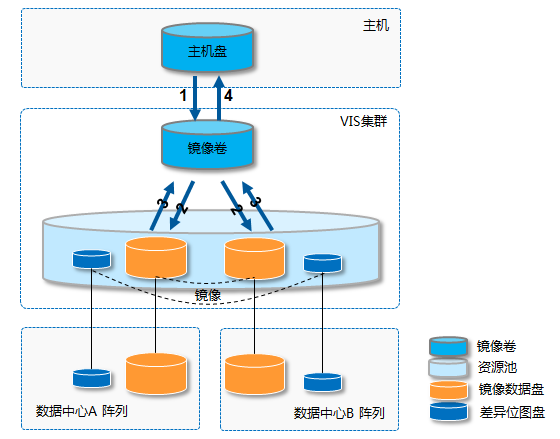
VIS镜像的写I/O流程如下:
1) 写请求到镜像卷;
2) 镜像卷将请求复制为两份下发到两中心的镜像数据盘;
3) 镜像数据盘返回写操作完成;
4) 镜像卷返回写I/O操作完成。
VIS镜像的读I/O流程如下:
1) 读请求到镜像卷;
2) 镜像卷根据读策略下发请求到其中一个中心的镜像数据盘;
3) 镜像数据盘返回读数据;
4) 镜像卷返回读数据。
当单阵列或单数据中心故障时,镜像卷选取正常数据中心的阵列响应主机I/O,并采用差异位图盘记录故障期间数据的变化情况,待故障修复后进行增量同步,从而减少数据同步量,缩短数据同步时间,降低数据同步对带宽的需求。
VIS镜像卷还支持3镜像技术,数据保存3份,进一步提高数据可靠性。
逻辑错误保护
当遭遇病毒攻击或人为误操作等异常时,数据中心的数据可能被破坏。华为存储双活解决方案采用VIS虚拟快照技术,在操作前对现有数据卷激活快照,实现本地数据保护。
虚拟快照采用写前拷贝(COW)技术,仅将变化的数据拷贝至快照卷,系统资源占用少。当原卷数据被错误修改或删除,需要进行恢复时,采用快照对原卷进行回滚,实现数据恢复,并且,快照卷可分别映射给主机进行数据测试和挖掘,不影响生产业务。结合华为容灾管理软件,激活快照前触发数据库完全检查点,待数据下盘完成后,激活快照,保证快照数据完全满足数据库的一致性要求,快速拉起数据库。
2.2.2 同城跨中心存储双活访问
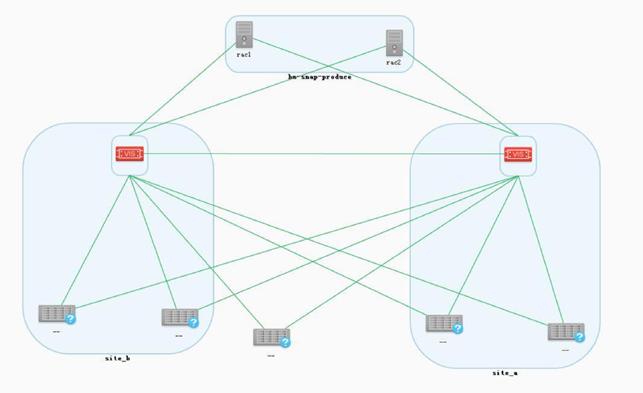
跨中心存储集群
华为存储双活解决方案利用VIS集群技术提供双活的存储架构,该架构包含4节点的VIS集群;每个节点以共享卷方式向应用服务器提供无差异的并行访问,同时处理应用服务器的I/O请求;各节点间互为备份,均衡负载,任何节点故障后,其承接的业务自动切换到正常节点,保证系统的可靠性、业务的连续性。其工作原理如下图所示。
图2-3 VIS集群工作原理
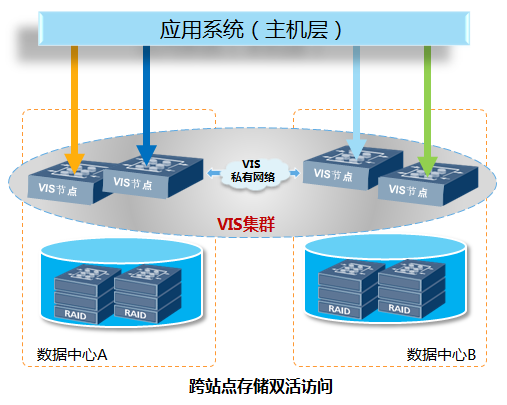
该设计具有以下优势:
l 均衡负载
通过持续监视主机到VIS各节点的路径,将I/O请求平均分配到各路径,优化系统的整体性能。
l 高可用性
当一个或多个VIS节点发生故障时,剩余节点会快速地感知并自动接管故障节点的业务,保证业务连续运行。
为保证各种异常情况下,存储虚拟化集群能够进行仲裁,存储双活方案需要设计第三方仲裁站点,以保证极端场景下的业务连续性。极端场景包括:出现数据中心整体故障或中间链路故障等场景,虚拟化存储集群仍然可以访问至少两块仲裁盘进行仲裁,保证业务可靠性和数据一致性。
仲裁过程:
1. 双活数据中心之间的中间链路断开,导致两个数据中心集群发生分裂,进而两个中心之间的存储虚拟化平台发生“脑裂”,存储虚拟化平台从一个大集群分裂为两个小集群;
2. 根据集群“脑裂”的原理,当大集群分裂为两个小集群时,每个小集群分别抢占存放第三方仲裁信息的仲裁盘,抢占到51%以上仲裁信息(即抢占到2个仲裁盘)的小集群“获胜”,将继续对外提供服务,为应用提供存储访问空间;
3. 未抢占到仲裁信息的小集群则自动退出集群,不再对外提供服务;
4. 当中间链路恢复时,“自动退出的小集群”检测到中间链路由故障变为正常,尝试与“继续服务的小集群”握手通信,经过握手通信两个小集群再次组成一个大集群,以Active-Active模式提供服务,互相之间实现冗余。
图2-4 VIS集群仲裁原理
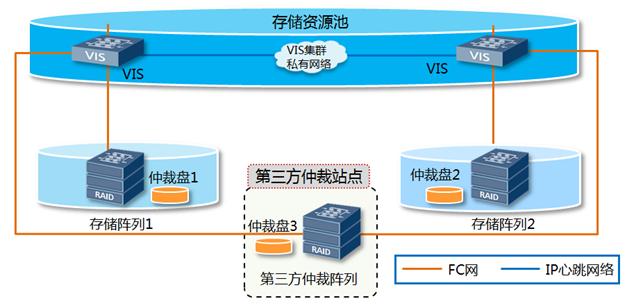
园区内的数据中心都是故障域,需要在故障域外(即第三方站点)配置仲裁阵列,出于成本考虑,建议配置IP SAN即可;
配置3个仲裁盘(1G大小),站点A阵列提供一个,站点B阵列提供一个,仲裁阵列提供一个;
故障不间断访问
存储双活解决方案,在各单部件和链路故障,甚至整个数据中心故障,都可以实现业务自动无缝切换。
以下列举各种故障场景的连续性分析:
1.故障场景:VIS单控制器故障
图2-5 VIS单控制器故障示意
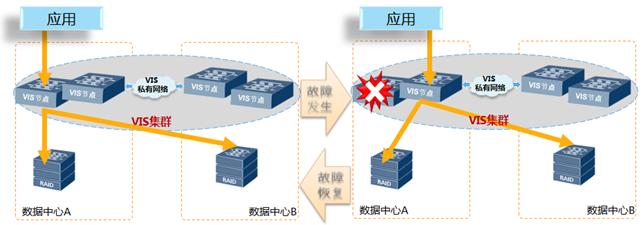
每个数据中心各部署一台双控冗余配置的VIS,构建一个跨数据中心的4节点VIS集群。当VIS的其中一个控制器发生故障时,同数据中心的VIS节点自动接管其虚拟化,业务主机I/O自动切换到本数据中心的VIS节点,不会发生跨数据中心切换。假设数据中心A的VIS控制器1故障,处理过程如下:
1) VIS集群检测到VIS节点控制器故障,将该VIS节点踢出集群;
2) 主机多路径检测发现主机到VIS控制器1的路径故障,将路径自动切换到本数据中心VIS的控制器2进行I/O访问;
3) 两个数据中心业务不发生切换,正常运行;主机业务写I/O,通过VIS镜像,仍然实时同步写到两个数据中心的阵列;读I/O保持从本地VIS读取,不会跨数据中心读取数据。
数据中心A的VIS节点故障恢复后,VIS集群自动重组集群,多路径软件优先选择本地VIS节点,将访问路径切回原来VIS节点,上层业务无影响;
2.故障场景:单中心VIS故障
图2-6 单中心VIS故障示意
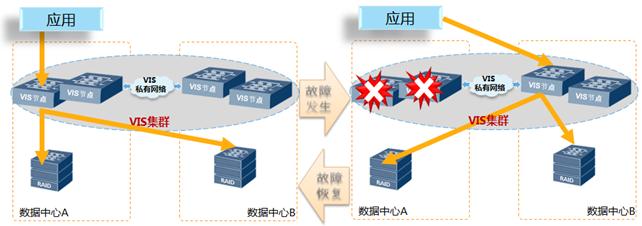
存储双活方案,两个数据中心的VIS构建的是跨数据中心集群,当其中一台VIS故障时,另一数据中心虚拟化网关设备自动接管虚拟化,业务主机I/O自动切换,业务无中断。假设数据中心1的一台VIS设备故障,处理过程如下:
1) VIS集群检测到数据中心A的VIS故障,将故障VIS节点踢出集群,正常VIS节点自动接管虚拟化卷;
2) 主机多路径检测发现主机到数据中心A的VIS路径故障,将路径自动切换到数据中心B的VIS进行I/O访问;
3) 两个数据中心业务不发生切换,正常运行;主机业务I/O,通过VIS镜像,仍然实时同步写到两个数据中心的阵列;读I/O从数据中心2的存储阵列读取。
数据中心A的VIS故障恢复后,VIS集群自动重组集群,多路径软件优先选择本地VIS节点,将访问路径切回数据中心A的VIS节点,上层业务无影响;
3.故障场景:阵列故障
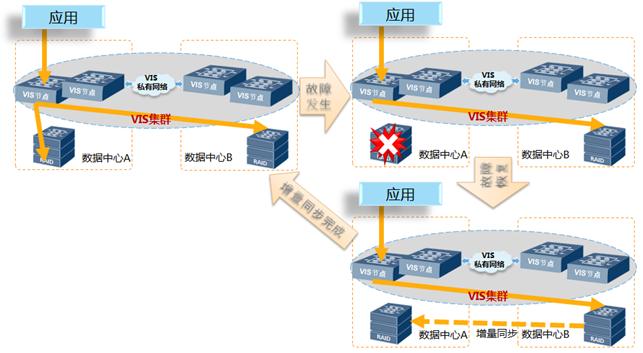
存储双活方案,每个数据中心各部署2台存储阵列,通过VIS镜像功能,两个数据中心的阵列跨数据中心镜像,数据实时同步。当单数据中心一台阵列故障时,业务I/O自动切换到另一数据中心的镜像阵列处理,业务无中断。假设数据中心A的一台阵列故障,处理过程如下:
1) VIS集群检测到数据中心A的阵列故障,VIS将该阵列盘状态置为‘disable’, VIS镜像关系故障;
2) VIS后端磁盘多路径检测发现VIS到该故障阵列的路径故障,将路径自动切换到数据中心B的镜像阵列进行I/O访问;
3) 两个数据中心业务不发生切换,正常运行;主机业务写I/O只写到数据中心B的阵列,并记录新增数据位图,标识数据中心A与数据中心B阵列之间差异;读I/O从数据中心B的存储阵列读取。
数据中心A的阵列故障恢复后,手动恢复镜像关系,根据差异位图盘的记录自动同步新增数据,上层业务无影响;
4.故障场景:站点链路故障
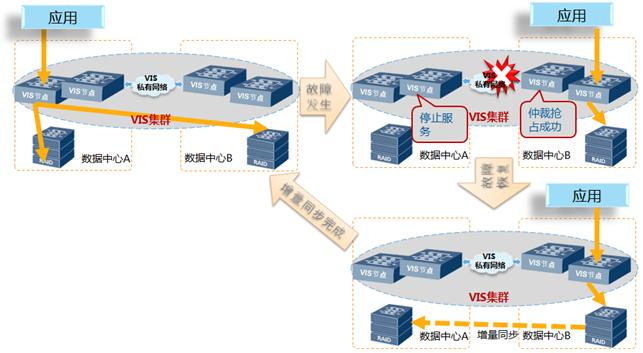
同城网络包括业务数据镜像网络、VIS集群网络和Oracle RAC私有网络,当同城网络故障时,通过VIS集群的仲裁机制,仲裁抢占胜利的VIS对应的数据中心则接管所有的业务,业务自动切换。详细处理过程如下:
1) 同城网络链路故障,VIS集群检测到集群心跳网络链路故障,集群开始仲裁;
2) 如果数据中心B的VIS仲裁抢占胜利,数据中心A的VIS重启,踢出集群;数据中心B的VIS无法访问到数据中心A阵列,VIS将该数据中心A的阵列盘状态置为’disable’, VIS镜像关系故障;
3) 对于Oracle来说,RAC集群检测到数据中心A的RAC服务器到数据中心B的VIS链路故障,业务I/O不能正常访问,数据中心A的RAC自动切换到数据中心B;对于VMware或FusionSphere来说,主机集群检测到数据中心A的主机到数据中心B的VIS链路故障,业务I/O不能正常访问,数据中心A的虚拟机自动切换到数据中心B;
4) 主机业务写I/O只写到数据中心B的阵列,并记录新增数据位图,标识数据中心A与数据中心B阵列之间差异;读I/O从数据中心B的存储阵列读取。
同城链路修复后,自动重组VIS集群,手动恢复镜像关系,VIS根据差异位图盘的记录自动同步新增数据,上层业务无影响;
5.故障场景:站点故障
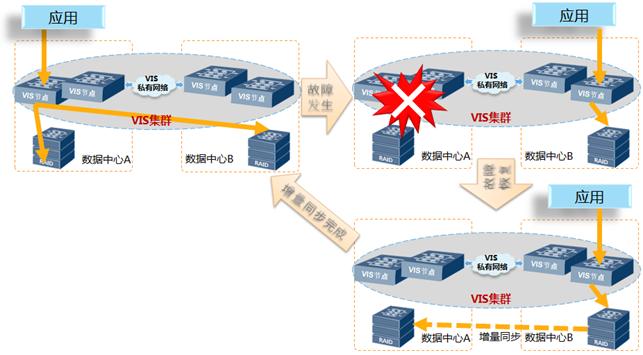
存储双活方案,设备全冗余架构部署,当一个数据中心发生停电或火灾等灾难时,另一个数据中心VIS对应的数据中心则接管所有的业务,虚拟机业务自动切换。详细处理过程如下:
1) VIS集群检测到数据中心A的VIS故障,集群重构,踢出集群;数据中心B的VIS无法访问到数据中心A阵列,VIS将该数据中心A的阵列盘状态置为’disable’, VIS镜像关系故障;
2) 对于Oracle来说,RAC集群检测数据中心A的RAC服务器故障,数据中心A的业务自动切换到数据中心B;对于VMware或FusionSphere来说,主机集群检测数据中心A的主机故障,数据中心A的虚拟机自动切换到数据中心B;
3) 主机业务写I/O只写到数据中心B的阵列,并记录新增数据位图,标识数据中心A与数据中心B阵列之间差异;读I/O从数据中心B的存储阵列读取。
修复故障数据中心后,自动重组VIS集群,手动恢复镜像关系,VIS根据差异位图盘的记录自动同步新增数据,上层业务无影响;
地域优化访问
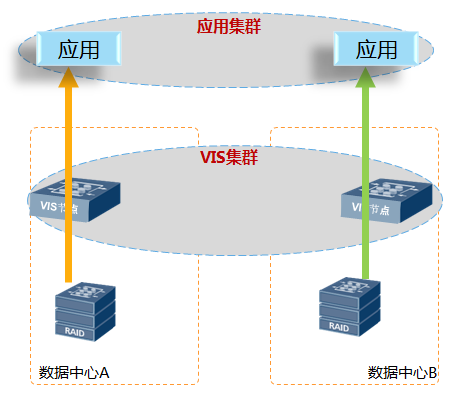
1.优化读
针对双活数据中心场景,VIS设计了“Site Read”模式,以避免VIS跨数据中心读取数据,提升方案整体性能。其读I/O流程如下:
1) 读请求到镜像卷;
2) 镜像卷根据策略下发请求到与VIS在同一个数据中心的镜像数据盘读取数据;
3) 镜像数据盘返回读数据;
4) 镜像卷返回读数据。
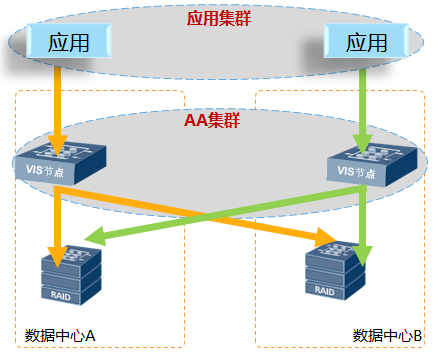
2.优化写
针对双活数据中心场景,两站点的距离较远,网络传输时间成为影响系统性能的主要瓶颈,减少跨数据中心访问次数是优化写流程的重点。
存储的集群模式,业界有AA集群和AP集群之分。
AP集群只有主站点的主控制器可以读写数据,针对上述限制,采用AP集群技术的厂商针对双活场景提供两种技术实现双活访问:
1) 备站点的主机访问备站点的备控制器,备控制器跨站点转发给主站点的主控制器,由主控制器访问数据;
2) 备站点的主机通过多路径软件跨站点访问主站点的主控制器,由主控制器访问数据;
上面两种技术,都会导致多次跨数据中心访问,严重影响性能;

AA集群的每个节点都能够承接写IO,由本地节点处理本地主机的写IO请求,避免主机将写IO发给跨数据中心的存储,减少跨数据中心的访问次数,提升方案整体性能。
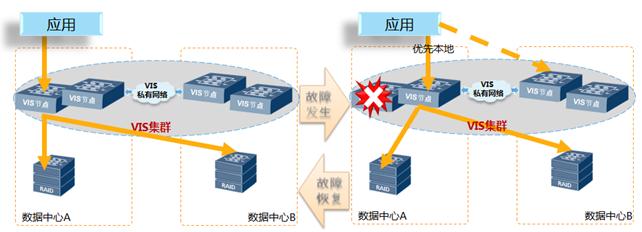
3.故障优化读写
针对双活数据中心场景,多路径软件支持优选本地路径模式,在这种模式下,多路径软件将优先使用本地VIS节点来下发I/O,只有当本地节点路径故障后才跨数据中心访问远端VIS节点。
2.2.3 异地跨中心数据保护
同城双活中心的建设,可以消除常见意外导致的业务中断问题,包括:停电检修,意外断电,火灾,日常演练等。但对于罕见的区域灾难,比如地震等,需要在同城双活中心的基础上,建设异地灾备中心;
华为双活架构支持平滑升级,无需改造生产系统,只要在异地数据中心部署一台存储和存储并创建和双活数据中心共享卷一样大小的备份卷,建立双活数据中心共享卷和异地灾备中心备份卷的远程复制关系;
2.2.4 可视化管理
双活容灾管理软件提供可视化管理,支持展示双活物理拓扑图与业务逻辑拓扑,链路故障告警等支持可视化展示双活物理拓扑,并能监控各网元(主机、虚拟化网关、磁盘阵列)的状态;支持可视化展示双活逻辑拓扑,呈现应用-VIS-存储的端到端映射关系和数据流向;
2.3 网络设计
2.3.1 方案组网图
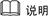
两数据中心的VIS与第三方仲裁站点存储阵列的链路可根据需要采用IP网络或FC网络。
华为存储双活解决方案组网如上图所示,主要包含三个部分:集群互连的心跳网络、主机与存储互连的SAN网络、以及数据中心间互连的同城网络。
l 心跳网络
心跳网络主要包含Oracle RAC、VMware集群、FusionSphere集群和VIS心跳网络。为保证单链路故障时,业务无影响,建议心跳网络采用全冗余设计,Oracle RAC和VIS集群节点都配置两个网卡,确保节点间有两条链路互通。
l SAN网络
主机到VIS以及VIS到存储阵列的SAN网络,都采用FC双交换组网,并分别通过主机多路径软件UltraPath和VIS多路径软件实现链路的冗余和容错。
l 同城网络
方案采用DWDM设备,将多路FC信号和IP信号复用到光纤链路上传输,保证较低的传输时延和稳定的带宽,实现100km内存储双活互连的同城传输网络。
2.3.2 同城网络设计
通常数据库应用对存储系统处理时延要求比较苛刻。根据经验,当存储系统I/O处理时延小于10ms时,Oracle数据库性能表现较好;大于20ms时,存储系统可能成为整个业务系统的瓶颈。存储双活方案采用VIS镜像技术跨同城网络实时同步数据,对于写I/O,两数据中心存储阵列都写成功之后才会回复主机写完成。因此,如何构建长距离、高带宽、低时延的同城传输网络,是存储双活方案设计的重点。
长距离、高带宽网络设计
由于直接使用裸光纤将两个数据中心网络相连存在传输距离短、带宽利用率低等限制,本方案采用DWDM技术,用低损耗单模光纤作为传输介质,激光器光源以极小的角度将光波信号打入单模光纤的纤芯中进行传输,端到端光波路径近似直线,整个过程光波能量损耗极小。当前,无中继最大传输距离支持600km,满足存储双活方案同城网络长距离传输的需求。
DWDM技术在一根光纤中实现多路光信号的复用传输,单纤最大可提供40G*80波,高达3.2Tbits/s的传输带宽。华为DWDM设备的距离扩展功能,通过对FC帧提前应答,解决了FC业务固有的长距离传输带宽急剧下降问题,保证FC跨数据中心传输带宽的稳定性。
部分低端DWDM设备(如Optix OSN1800)不支持距离扩展功能,可通过交换机的距离拉远功能来保证FC长距离传输带宽的稳定性。
低时延网络设计
同城传输网络时延主要由以下几部分构成:
|
时延单元 |
时延值 |
|
光纤/尾纤 |
500us/100km |
|
色散补偿 |
DCF补偿方式:约81us/100km |
|
FBG补偿方式:50ns(与距离无关) |
|
|
前向纠错 |
42.32us~126.97us |
|
业务汇聚板 |
< 20us(取决于信号的封装映射方式) |
|
光放大器、光器件、其他单板 |
几乎为0,可忽略 |
方案针对以上各时延产生单元的优化措施如下:
l 光纤传输距离优化
光在光纤中的传输时延约5us/km,是同城传输网络的主要时延产生单元。由于光传输速率是固定的,建议通过优选路由和缩短路由来减小两中心间的光传输距离,优化网络传输时延。
l 色散补偿优化
光网络色散补偿有负向色散补偿光纤(DCF)和布拉格光栅(FBG)两种方式,它们产生的时延如下表:
|
传输距离(km) |
DCF(us) |
FBG(us) |
|
80km |
65 |
0.05 |
|
100 km |
81 |
0.05 |
|
120 km |
97 |
0.05 |
因此,方案建议采用FBG补偿方式代替传统的DCF补偿方式,有效降低同城网络传输时延。
部分低端DWDM设备(如Optix OSN1800)不支持FBG色散补偿方式。
l 前向纠错优化
前向纠错 (FEC)是实现长距离传输的一个关键技术,华为DWDM设备支持三种级别的FEC解码方式,它们的纠错能力及时延如下表:
表2-3 各级FEC纠错能力及时延
|
解码方式 |
纠前误码率 |
纠后误码率 |
NCG-解码增益(dB) |
时延值(us) |
|
一级解码 |
2.17E-3 |
1E-15 |
8.5 |
42.32 |
|
二级解码 |
2.07E-3 |
无 |
8.53 |
84.64 |
|
三级解码 |
3.04E-4 |
无 |
6.98 |
126.97 |
建议通过合理的网络规划,提升光信噪比(OSNR)余量,减少使用FEC带来的时延。(OSNR)余量充足的场景,选择一级解码以减少时延;OSNR余量较小的场景,优先选择二级解码。
l 业务汇聚板选择
DWDM设备的业务汇聚板包含业务板和合波/分波板。它们带来的时延如下表:
|
业务汇聚板类型 |
时延值(us) |
|
合波/分波板 |
10 |
|
业务板 |
波长转换类业务板:10~15 |
|
支路线路类业务板:20 |
DWDM技术单波长信道最大可提供40Gbps的传输带宽,当数据中心间带宽需求小于40Gb/s时,建议不使用合波/分波板,只使用业务板完成业务汇聚。由于波长转换类业务板信号处理方式更加快捷,比支路线路类业务板时延更低,建议优选波长转换类业务板。
短距离、低成本网络设计
华为存储双活方案可依托多种传输技术灵活组网,满足不同用户、多种应用场景的需求。当两个数据中心之间的传输距离小于等于30km时,可采用裸光纤直连组网,从而简化组网方式、降低方案成本。
2.4 应用设计
Oracle RAC双活设计
Oracle RAC以共享存储为基础,通过共享的存储资源,实现各节点对数据文件、重做日志文件、控制文件和参数文件的并行访问,且在单个节点出现故障时,业务能自动切换到正常节点,从而保证数据库系统正常可用。
存储双活方案采用共享卷技术,将跨数据中心的存储以共享方式提供给上层应用访问,满足Oracle RAC的共享存储需求,实现跨数据中心的Oracle Extended RAC集群构建。
Oracle Extended RAC集群配合Oracle监听器技术,可实现客户端在数据中心间业务双活访问和负载均衡;配合Oracle透明应用程序故障转移(TAF)技术,当服务器或单数据中心故障时,使客户端能够在新的连接中继续工作,防止业务中断。
VMware双活设计
VMware集群以共享存储为基础,通过共享的存储资源,两个数据中心分别部署多台ESXi主机,组成VMware vSphere集群。
方案结合VMware HA功能,保证当任一主机或单数据中心故障时,业务虚拟机可以自动切换到正常的主机运行,数据无丢失,业务中断时间趋近于零。
方案结合VMware DRS功能,业务虚拟机可跨数据中心自动实现负载均衡,实现主机资源均衡分配使用。
当系统需要计划内维护或者主机资源重新分配时,可通过vMotion功能手动将业务虚拟机在主机间迁移,迁移过程中业务不中断。
FusionShere双活设计
FusionShere集群以共享存储为基础,通过共享的存储资源,两个数据中心分别部署多台CNA主机,组成FusionShere集群。
方案结合HA功能,保证当任一主机或单数据中心故障时,业务虚拟机可以自动切换到正常的主机运行,数据无丢失,业务中断时间趋近于零。
方案结合DRS功能,业务虚拟机可跨数据中心自动实现负载均衡,实现主机资源均衡分配使用。
当系统需要计划内维护或者主机资源重新分配时,可通过迁移功能手动将业务虚拟机在主机间迁移,迁移过程中业务不中断。
2.5 方案组件
本次方案涉及业务网络、业务主机、SAN网络、虚拟化智能存储、磁盘阵列、交换机、波分复用等设备。表1-1描述了解决方案所需要的必备组件 。
|
必备组件 |
描述信息 |
|
数据库服务器 |
搭建Oracle RAC环境所需的数据库服务器,建议为3台,跨站点部署为“2+1”的数据库集群。 |
|
虚拟化主机服务器 |
搭建VMware/FusionShere环境所需的数据库服务器,建议4台,两个数据中心各部署2台. |
|
以太网交换机 |
建议4台,两个数据中心各部署2台,通过交换机提供VIS6600T集群心跳,心跳端口为GE端口,上层业务访问与Oracle RAC集群心跳,集群心跳建议采用10GE。 |
|
波分复用设备 |
两个数据中心各部署1台。 |
|
FC交换机 |
光纤交换机4台,按端口数量配置相应的光纤交换机,需要按逻辑拓扑连线进行Zone的配置。 |
|
VIS6600T(虚拟化智能存储) |
2台共4节点,跨数据中心组成4节点集群。 |
|
磁盘阵列 |
存储生产数据,至少2台,两个数据中心各放置1台。 |
|
第三方仲裁存储单元 |
1台,建议配置低端阵列,放置在第三站点,可通过iSCSI连接存储虚拟化智能存储。 |
3 关键组件介绍
3.1 华为OceanStor 18000系列产品
OceanStor 18000系列高端存储系统是华为自主研发的存储高端旗舰产品系列,包括OceanStor 18500和OceanStor 18800两种型号,致力于为企业级数据中心提供安全可信、弹性高效的核心存储解决方案。
OceanStor 18000系列基于Smart Matrix智能矩阵架构和全虚拟化专用操作系统,最大扩展至16个控制器、3,216块硬盘、7,168TB容量,192GB系统带宽、3TB Cache,192个主机接口(FC/FCoE/iSCSI),最大支持65,536台服务器共同使用。
软件方面,OceanStor 18000系列配备SMART系列资源管理软件和Hyper系列数据保护软件,最大提升资源利用效率、提供关键业务智能优先保障和7*24业务可用性。
OceanStor 18000系列采用整柜交付的模式,支持机柜分散布放。

3.2 华为VIS产品
华为VIS6000T系列(以下简称VIS)是业界领先的存储虚拟化产品,全冗余硬件保证无单点故障,确保7×24小时的持续可用。本方案利用VIS提供的以下关键技术,构建存储双活解决方案架构。
华为OceanStor VIS6600T(以下简称VIS6600T)是业界领先的存储虚拟化产品,满足客户异构存储整合、存储空间统一管理、多级容灾系统构建等需求,实现资源整合、统一管理、数据迁移和多重数据保护,为客户构建安全可靠、管理灵活、高性能、开放的存储系统。是实现双活数据中心解决方案的核心部件。

3.3 华为OptiX OSN 系列OTN设备
Mini OTN系统OptiX OSN 1800,率先结合了OTN及WDM特性,协助能源、教育、金融、政府、大企业等行业将接入传送统一到一张网络上,解决了接入传送中面临的各种问题。同时,创新性地将ITU-T G.709 OTN 标准适配范围扩展至2M~10G。
l 各种业务统一传送,简洁组网
业务统一承载,简化组网。通过“All over WDM/OTN”方式,从低速率业务(如E1)到大带宽业务(如任意协议的10G业务)全部封装到OTN帧格式中进行统一传送,可以广泛传送DSL、FTTx、专线等业务。
长距传送,减少网络节点。业界首次在接入WDM上引入G.709 OTN标准。支持标准OTN FEC,可以实现140km(39dB)传送距离,远超过传统CWDM传送80km的限制。
业界最强大的业务汇聚能力和集成度,减少设备数量。OSN 1800支持单卡2*GE+2*FE、2*GE+2*STM-1、4*GE、8*GE、4*Any、8*Any、8*EPON、4*GPON 等高密度汇聚能力。所有板卡只占用一个槽位,5G线路速率以下的板卡均内置“双发优收”保护。
l 减少维护投入,降低维护成本
网络简洁化,减少节点费用。WDM/OTN的大容量统一传送和长距离传送能力使得网络简洁化成为可能:组网上,业务设备与网管和OSS系统集中配置在中心节点;传送等功能简洁的设备,分散部署在无人的机房,实现广覆盖。这种“头脑集中、四肢简单”的网络结构有助于大幅提升维护效率,减少维护工作量。
OTN GCC带内开销,可靠管理。支持传统光监控信道(OSC)和G.709 OTN 带内管理(ESC)两种模式,确保在不增加任何网管系统投资的情况下,即可实现所有SDH、WDM/OTN设备统一管理,统一维护。此时网管信息不通过IP网络,严格保证安全性。支持无风扇设计,无须维护。由于消除了风扇本身故障,进一步提高可靠性。
l 绿色环保,节电降耗
相比核心层设备,接入层设备数量庞大,节能尤为重要。
统一组网,整网降耗。OSN 1800的多业务统一传送特性把接入传送网络简化到一张网,避免建设多张传送网络,大大减低整网功耗。
网络瘦身,精简节点。创新的“All over WDM/OTN传送拉远”技术实现网络瘦身,业务设备可以集中放置在大局点,通过拉远方式直接连接到用户端,节省中间节点数量30%~90%,减少节点建设费用和管理费用。
台灯式低功耗设计。1U设备在单站点2*GE的典型配置下,功耗约25W,还不到一盏台灯的耗电量。
l 平滑升级,保护投资
OSN 1800支持“单波白光、8波CWDM、40波DWDM”的升级扩容,以及CWDM、DWDM混合组网,能够满足网络容量逐步发展要求,保护客户的投资。
光模块全部可插拨,即插即用,可重用降低了备件投入。
3.4 Oracle RAC产品
3.4.1 Oracle RAC 简介
Oracle RAC是Oracle数据库高可用技术之一,也是Oracle数据库支持网格计算环境的核心技术,可提供多节点并发的数据库应用,并通过监听客户端和服务器端实现负载均衡,把用户连接分配到不同的节点上执行。
Oracle Extended RAC在Oracle RAC技术基础上提供了一种跨数据中心的双活集群架构,当单中心故障时,另一个数据中心可自动接管业务,接管过程对上层业务透明,用户无感知。
对于Oracle Extended RAC架构,Oracle建议两个数据中心间距离不超过100km,确保时延在1ms之内。
3.4.2 方案Oracle RAC配置
华为双活数据中心解决方案与Oracle Extended Distance Cluster最佳实践的测试业务模型Profile的选择依据:是通过对一个中大型企业的ERP系统进行调研得出的,其ERP系统后台为Oracle数据库,业务高峰期从8:00至18:00。
|
类别 |
值 |
备注 |
|
数据库类型 |
OLTP |
|
|
读写比例 |
60:40 |
|
|
连接Oracle RAC数据库的并发用户数 |
4800 |
4800并发用户属于大压力场景 |
|
Oracle RAC服务器节点个数 |
3 |
数据中心A部署2个节点、数据中心B 部署1个节点 |
|
数据总量 |
10TB |
|
|
数据保存周期 |
3年 |
|
|
每小时产生的Redo量 |
51.4GB |
每个节点每7分钟产生一个2GB的redo日志 |
|
归档日志保存周期 |
3个月 |
3.5 VMware vSphere
3.5.1 VMware vSphere 简介
VMware vSphere虚拟化平台将应用程序和操作系统从底层硬件分离出来,简化了IT操作。ESXi主机是vSphrer平台的核心组件,多台ESXi 主机可以组成集群,集群内所有主机的处理器、内存、网络等资源被虚拟化为公用资源池。虚拟机的运行基于被分配的专用资源,其资源使用相互独立。集群合理配置后,虚拟机可以在集群内动态在线迁移。
3.5.2 VMware vSphere 配置
华为双活方案在数据中心1和2分别部署了2台VMware ESXi主机,通过网络将4台主机组成一个集群。ESXi主机集群配置HA和DRS功能,集群部署了共3台虚拟机,初始配置数据中心1和2的应用情况如下表示:
|
数据中心 |
应用 |
数量 |
|
1 |
SQL Server |
1 |
|
域控服务器 |
1 |
|
|
vCenter Server |
1 |
vSphere集群架构配置时建议:
l 两个数据中心ESXi主机管理网络配置为同一个IP网段,且vCenter Server与ESXi主机也配置为同一IP网段。
l 两中心虚拟机的操作系统以及数据必须放在共享空间,并确保集群的所有ESXi主机可以访问。
l vMotion的网络必须为IP网络,且带宽不小于1Gb/s。
l 若应用部署在MSCS集群上,集群节点所在虚拟机需在关机状态下vMotion。
3.5.3 应用配置
Microsoft SQL Server配置
方案采用OLTP业务标准测试工具TPCC-Runner,读写比例3:2,数据量300GB的测试环境进行SQL Server应用验证。SQL Server测试环境中虚拟机的资源配置如下表:
表3-3 SQL Server测试环境虚拟机配置
|
服务器角色 |
数量 |
vCPUs |
内存(GB) |
系统盘(GB) |
数据盘(GB) |
日志盘(GB) |
|
SQL Server |
1 |
4 |
24 |
50 |
800 |
200 |
3.6
4 方案验证
4.1 可靠性验证
本章主要介绍两数据中心相距100km场景下,方案可靠性验证结果。
表4-1 可靠性验证结果(Oracle场景)
|
故障场景 |
测试用例 |
结果 |
|
部件故障 |
单中心所有RAC节点服务器故障 |
通过。业务不中断 |
|
单中心VIS故障 |
通过。业务不中断 |
|
|
单中心阵列故障 |
通过。业务不中断 |
|
|
第三方仲裁盘故障 |
通过。业务不中断 |
|
|
链路故障 |
同城IP链路故障 |
通过。业务不中断 |
|
同城FC链路故障 |
通过。业务不中断 |
|
|
同城IP和FC链路故障 |
通过。业务不中断 |
|
|
站点故障 |
单数据中心故障 |
通过。业务不中断 |
表4-2 可靠性验证结果(VMware和FusionSphere场景)
|
故障场景 |
测试用例 |
结果 |
|
环境链路故障 |
两数据中心间主机通信故障 |
通过。业务不中断 |
|
两数据中心间所有链路同时故障 |
通过。虚拟机自动切换到正常数据中心,业务恢复正常 |
|
|
环境部件故障 |
单数据中心主机全部故障 |
通过。虚拟机自动切换到正常数据中心运行,业务恢复正常 |
|
单数据中心VIS故障 |
通过。业务不中断 |
|
|
单数据中心阵列故障 |
通过。业务不中断 |
|
|
第三地仲裁盘故障 |
通过。业务不中断 |
|
|
单数据中心故障 |
单数据中心所有部件全部故障 |
通过。虚拟机自动切换到对端,业务恢复正常 |
4.2 性能验证
4.2.1 Oracle性能测试
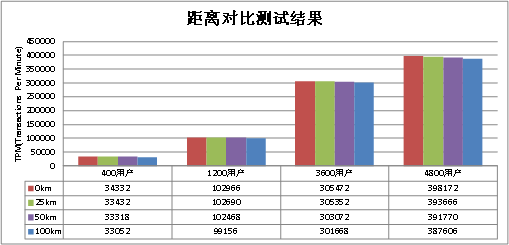
本章主要介绍方案的性能测试结果。使用标准OLTP负载(读写比例60/40),在多组并发用户数下,测试拉远100km存储双活方案和本地高可用方案的性能。这两种方案每分钟处理的事务数(TPM)如下图所示,当并发用户数相同时,拉远100km存储双活方案和本地高可用方案相比,事务处理能力基本无影响。
Oracle数据库读操作采用同步方式,写操作采用异步方式。当拉远100km时,存储双活方案对读操作进行优化,实现数据库在本地数据中心读取数据,从而避免距离对读性能造成影响;数据库写操作采用写主机缓存的异步方式,数据没有实时下盘,虽然拉远100km后,对比本地高可用方案数据下盘延迟增加,但依然在Oracle数据库可接受的10ms范围内,对性能没有影响。所以,拉远100km双活方案和本地高可用方案相比,事务处理能力基本无影响。
4.2.2 Microsoft SQL Server性能测试(Vmware场景)
测试工具使用TPC-C Runner模拟OLTP业务类型。
SQL Server 性能测试结果图示如下:
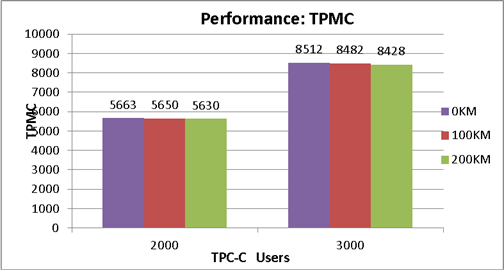
由如上TPMC性能结果图示可以看出,在相同并发用户数时,双活数据中心相距0km、100km和200km时的事务处理能力(TPM)几乎一致。由于存储双活方案在拉远时对读操作进行优化,实现数据库在本地数据中心读取数据,从而避免距离对读性能造成影响;数据库写操作采用写主机缓存的异步方式,数据没有实时下盘,所以,双活数据中心相距0km、100km和200km时的事务处理能力基本一致。
SQL Server服务器2000个用户场景,虚拟机跨数据中心(相距100km)vMotion时,如图4.2所示:
图4-3 SQL 服务器100km vMotion 的TPMC性能
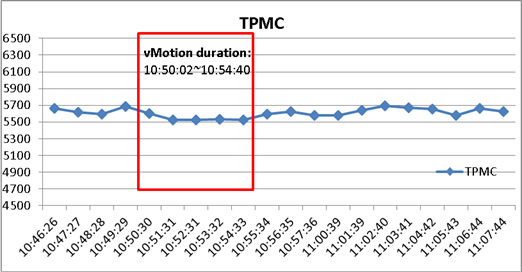
通过SQL服务器vMotion时的性能验证结果可以看出,在执行跨100km数据中心间SQL虚拟机vMotion时,事务处理能力(TPM)几乎无影响。
图4-4 SQL 服务器写性能
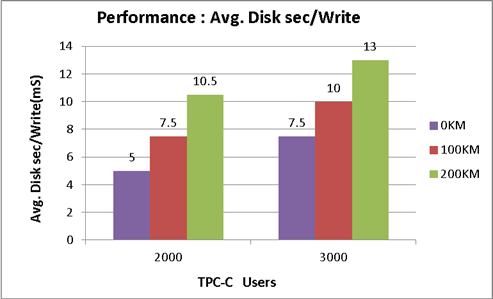
如上图所示,两数据中心相距0km、100km和200km时,IO写延时有一定影响,因为两个数据中心数据需要时刻保持一致,采用了镜像写策略,但是本方案的写IO延时仍然满足业界最佳值要求。
图4-5 SQL 服务器读性能

如上图所示,两数据中心相距0km、100km和200km时,IO读延时影响与写时延相比有了明显的降低,因为在方案中我们采用了Site Read技术。
5 总结
本白皮书描述了华为存储双活解决方案在Oracle RAC、VMware、FusionSphere场景下的应用。通过验证,拉远100km存储双活方案与本地高可用方案相比,事务处理能力基本无影响,且华为存储双活方案可保证单数据中心故障时,业务无缝自动切换,数据零丢失。
此外,华为存储双活解决方案架构不依赖于具体的应用,可方便的扩展到所有支持远程集群的应用系统。
6 缩略语
|
缩略语 |
英文解释 |
中文解释 |
|
VIS |
Virtual Intelligent Storage |
虚拟化智能存储 |
|
COW |
Copy on Write |
写前拷贝 |
|
FC |
Fibre Channel |
光纤通道 |
|
IP |
Internet Protocol |
Internet协议 |
|
iSCSI |
Internet SCSI |
互联网小型计算机系统接口 |
|
LUN |
Logical Unit Number |
逻辑单元号 |
|
NAS |
Network Attached Storage |
网络附加存储 |
|
DWDM |
Dense Wavelength Division Multiplexing |
密集型波分复用 |
|
PCI |
Peripheral Component Interconnect |
外围设备互联 |
|
RAID |
Redundant Array of Independent Disks |
独立磁盘冗余阵列 |
|
SAS |
Serial Attached SCSI |
串行SCSI |
|
SATA |
Serial Advanced Technology Attachment |
串行ATA |
|
SCSI |
Small Computer System Interface |
小型计算机系统接口 |
|
TCP |
Transmission Control Protocol |
传输控制协议 |
|
UPS |
Uninterruptible Power Source |
不间断电源 |
|
RAC |
Real Application Clusters |
实时应用集群 |
|
ASM |
Automatic Storage Management |
自动存储管理 |
|
FEC |
forward error correction |
前向纠错 |
|
DCM |
dispersion compensation module |
色散补偿模块 |
|
FBG |
fiber Bragg grating |
布拉格光栅 |
|
DCF |
dispersion compensation fiber |
色散补偿光纤 |
|
RPO |
Recovery Point Objective |
恢复点目标 |
|
RTO |
Recovery Time Objective |
恢复时间目标 |
|
TAF |
Transparent Application Failover |
透明应用程序故障转移 |
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。