| |
简易
Cluster 搭建
最近更新日期:2003/05/20
| 近年来因为数值模式模拟的盛行,所以‘平行运算’的架构也就越来越重要了!什么是数值模拟呢?主要就是藉由一些物理理论去开发出来的一些‘计算公式’,而这些计算公式藉由程序语言(例如C、Fortran等等)实际的将他编译成为可执行的程序,最常见的例如中央气象局不是每天都会预报天气吗?这个预报的动作就是利用数值计算去演算出来的。另外,还有空气品质模式模拟,也是经过运算出来的,除此之外,例如天文、物理、水文等等很多方面的工作,都是利用这种数值模拟的运算的喔!不过,这些程序是很大型的!也就是说,他们在运算的时间是很长的,如果使用单颗
CPU 的话,不论这颗 CPU 的频率与效能有多高,还是得要运算个好几个钟头的~如此一来,对于像气象预报这个急需时效性的工作可能就会有所延误啊!不过,如果我将这个运算的工作同时丢给多颗
CPU 呢?也就是让多颗 CPU 同时进行这个程序的运算工作,如此一来,将可以大大的减低时间的损耗了~这就是平行运算的简单说明。在
Linux 平台上面,要达成简单的平行运算,可以透过 MPI 的函式库,例如 MPICH
就是一个很有名的 MPI 软件喔!马上来给他看看平行运算类型的 Cluster 建置吧! |
原理:
:什么是
Cluster 与 Cluster 的优点
:Cluster
的主从架构
:达成 Cluster
所需要额外功能 ( RSH ) 与软件 ( MPICH )
搭建流程:
:整体架构
:鸟哥的一个实例规范
:系统安装 ( Red Hat
9 )
:防火墙
( 含 NAT 主机 ) 与网络设定
:NFS 搭建规划(相当重要,参考说明)
:NIS 搭建规划
:RSH 设定
:安装 Fortran 90 的编译程序
PGI pgf90 ( PS. server version )
:安装 MPICH
其他主机相关设定:
:X-Window
Server/Slave 架构
重点回顾
参考资源
原理:
-
什么是
Cluster 与 Cluster 的优点
什么是 Cluster 呢?目前常见的 Cluster (丛集)架构有两种,一种是 Web
/ Internet cluster system,这种架构主要是将资料放置在不同的主机上面,亦即由多部主机同时负责一项服务;而另外一种则是所谓的平行运算了!平行运算其实就是将同一个运算的工作,交给整个
Cluster 里面的所有 CPU 来进行同步运算的一个功能。由于使用到多个 CPU 的运算能力,所以可以加快运算的速度。目前比较常见于平行运算功能的,通常需要在超级电脑上面才看的到,这些超级电脑主要是用在天文、军事、物理等需要很精密的、大量的运算的工作中,而考虑到稳定性,则通常是用在
Unix 系统上面的硬体架构上。不过,目前由于 PC 上面的 CPU 的运算功能越来越强大了~因此,当然很多程序开发者就动脑筋到
PC 上面来制作平行电脑的系统啰!我们这篇短文主要在介绍的就是‘平行运算’这一类的
Cluster 了!
由于 Cluster 主要是用在平行运算上面的,而所谓的平行运算是使用到多颗
CPU 的运算功能,因此可以让您的大型运算的程序很快的执行完毕!因此,如果你的工作环境当中,常常会使用到很耗
CPU 运算功能的程序时,就可以尝试使用 Cluster 来进行工作啰!应该可以节省您不少的时间呐!此外,我们这篇短文主要是在
X86 架构下的 PC 来搭建 Cluster 的喔!
不过,也需要特别留意的是,由于我们的 Cluster 是将一个工作平均分给所有的
node (注:一颗 CPU 在一个 Cluster 架构下,就称为一个 node 啰!),所以,万一您做成的
Cluster 系统当中,所有的 node 并非完全相同的运算等级,那么先做完工作的
node 将会暂停工作,会等到所有的 node 都进行完毕后,才会在进行下一动~所以啦!强烈的建议在同一个
cluster 的架构中,尽量所有的 CPU 都使用相同的 CPU 型号,应该会比较好一点喔!
-
Cluster
的主从架构
最简单的 Cluster 其实就是以一种主从架构来进行资料的运算工作的,图示如下:
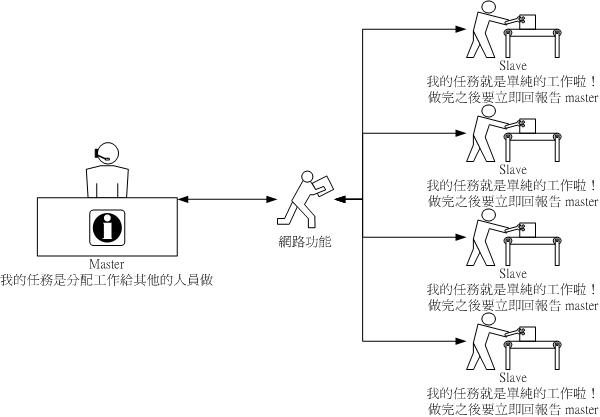
-
上面的 Master 与 Slave 指的都是 CPU 喔!
-
Master 那部机器上面必须要有可以将工作分配给各个 node
去工作的函式库,也就是 MPI ,他最重要的功能就是将工作给他分配下去的啦!而最重要的软件就是:(1)MPICH;(2)编译器(compiler,
例如 Fortran);
-
什么是网络功能呢?如果 master 与 slave 是在同一台机器当中,例如双
CPU 的主机板,那么这里就不需要网络功能啦!不过,如果我是使用四台双 CPU
的 PC 呢?呵呵!那么这四部主机就需要以高速网络架构进行连线啦!此外,还需要在这四部主机之间建立可以互通讯息的通讯协定才行,这方面的功能就含有:(1)R
Shell, 亦即称为 RSH;(2)NIS,使 Master 与 Slave 具有相同的帐号群组关系;(3)NFS,使读取写入的资料可以在同一个
partition 上面;
-
Slave 就是单纯的将来自 Master 的任务给他做完就是了!
整个主从架构大致上就是这样啦!因此,可以知道的是,我们需要的就是上面那些咚咚啰!
-
达成
Cluster 所需要额外功能 ( RSH ) 与软件 ( MPICH )
由上面的 Cluster 主从架构当中,我们知道 Master 与 Slave 之间的网络沟通很重要的一个咚咚,那就是
R Shell 啰!此外,还有将一个工作传送给不同的 node 来进行计算的任务,就需要
MPICH 这个函式库来进行!简单的谈一谈这两个玩意儿吧!
-
RSH:
在我们的 Linux 主机上面工作,通常使用 BASH 这个 shell 来传达给 kernel
工作的讯息,以使主机正确的工作;而如果在不同的主机之间,那就可以使用 R
Shell 来进行指令的下达喔,如此一来,我们就可以直接在 A 机器,向 B 机器下达工作的指令,而不需要登入
B 机器呢~那就是 RSH 的主要功能啦!最常见的 RSH 指令就是 rcp 与 rsh 了!有兴趣的朋友应该知道以
man 来查寻一下该指令的用法啰!
需要附带一提的是,这个 RSH 是‘相当危险’的一个服务喔!由于我们可以直接登入
RSH 主机,并且在上面进行指令的下达,为了避免还要输入密码的问题,因此通常
RSH 已经将信任主机设定好了,不过,由于 RSH 会启动一些 port 来监听 Clients
的需求,而偏偏这些 port 与 daemon 都还挺危险的,因此,‘Cluster 最好是设定在内部网络当中,并使用私有
IP ,比较能够避免危险’喔!此外,那个 Master 也必须要设定好一定程度的严密防火墙喔!
-
MPICH:
MPI 是 Messages Passing Interface 的缩写,他本身是一个规格很严密的通讯标准,主要的功能是在处理平行运算之间各个
node 的资料交换,请注意, MPI 并不是一套软件喔!而至于 MPICH 就是符合 MPI
这个标准通讯协定的一套软件了!因此,我们可以经由 MPICH 这个软件提供的 MPI
函式库来达成平行运算的功能喔!也就是说,我们所写的程序,只要能够使用 MPICH
提供的函式库,那么该程序就可以进行平行运算时候所需要的功能了,这就可以避免程序开发者还要去处理通讯节点上面的问题,而可以将程序开发的重心着重在程序本身的问题上面!
MPICH 是由 Mathematics and Computer Science Division的 Argonne 实验室所发展,详细的资料可以参考:http://www-unix.mcs.anl.gov/mpi/mpich/
除了这两个软件之外,还需要 NIS 与 NFS 喔!所以啦!要建置一个 Cluster
的话,身为系统管理员的您,必须要学会的技能真是相当的多的,至少需要:
-
熟悉 Linux 的操作技巧;
-
熟悉 Linux 基础网络参数设定;
-
熟悉 Linux 相关的 Server 搭建(这方面请参考鸟哥的私房菜搭建服务器篇);
-
了解 RSH 的相关功能与设定技巧;
-
了解 MPICH 的设定与相关功能;
-
熟悉至少一种程序语言。
还真的是不好学啊!鸟哥也是新手玩弄 Cluster 说~大家一起研究研究吧!
^_^
搭建流程
要搭建 Cluster 当然就是需要多部的 PC 来连线啦!不然怎么称为 Cluster
呢?您说是吧!所以,无论如何,在搭建 Cluster 之前,请务必要确认您的‘所有硬体以及网络功能都是完整无缺的!’否则就无法继续下去啦!另外,建议
Cluster 的所有主机规格尽量相同,可以避免等待的困扰呢!底下就来谈一谈整个搭建流程吧!
-
整体架构
整体架构的搭建当中,需要的所有软件为:
-
Master 主机安装需要:
-
防火墙的设定(含 NAT 搭建);
-
RSH
-
NIS Server
-
NFS Server
-
Compiler Install
-
MPICH Install
-
其他特殊功能
-
Slave 主机安装需要:
-
防火墙的设定
-
RSH
-
NIS Client
-
NFS Client
基本上,几乎所有的工作都是在 Master 上面做啦! Slave 最大的任务就是进行来自
Master 所要求的计算工作,因此,Slave 能够越简单越好~至于 Master 上面,由于我们都是在
Master 主机上面下达工作指令,而总不能老是在荧幕前面下达指令吧!因此上,Master
通常会有两个网络介面,分别是对外的 Public IP 与对内的 Priavte IP。而既然
Master 有提供 Public IP 的设定,自然就比较担心所谓的骇客入侵问题,所以啦,您的
Master 主机,要吗就不要开放 Public IP ,要吗就务必要设定很严密的防火墙,并且不必要的服务就尽量关闭他~毕竟我们的
Cluster 是要用来做为计算运作的,所以不必要的网络协定服务,当然就是关闭他啦!底下鸟哥将以自己的一个实际案例进行说明的啦!参考看看吧!
-
鸟哥的一个实例规范
在我这个案例当中, Cluster 主要的功能为:进行 MM5 这个气象模式的运算以及
Models-3/CMAQ 这个空气品质模式的运算,而由于这两个咚咚都是使用 PGI Fortran
90 做为 Compiler ,因此,我就必须要进行 PGI 的安装啦!而我的硬体架构主要是这样的:
-
Master : 为双 CPU 主机,使用 AMD MP 的 CPU ,并且有一颗 120 GB 的硬碟,此外,由于我的数值模式需要
PGI Fortran ,所以就必须要安装 Server 版的 PGI Fortran 喔!
-
Slave : 共有三部 Slave ,每一台均为双 CPU 的 AMD MP 的 CPU ,并且有一颗
120 GB 的硬碟;
-
连接 Master 与 Slave 的为 10/100/1000 的 Switch ,当然,四部主机(1 x master
+ 3 x slave)都是安装 Intel 的 1GB 网络卡喔!
硬体连接有点像这样:
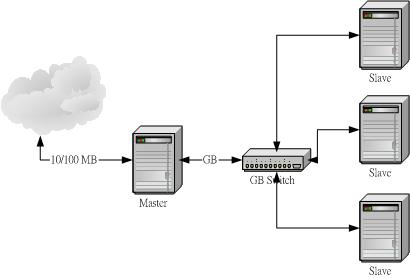 那么底下就来谈一谈怎么安装他吧!
那么底下就来谈一谈怎么安装他吧!
-
系统安装(
Red Hat 9 )
我的这个系统使用的是最新的 Red Hat 出版的 Red Hat 9 ,会用这个玩意儿最大的原因是因为
Red Hat 是目前支援的 Linux 软件最多的一个 Linux Distribution 了,安装他之后,就比较不会欠东欠西的,此外,很多的软件都是以
Red Hat 做为测试的平台,因此我就选择他来做为我的系统平台啊!另外,需要留意的是,由于
Slave 并不需要使用到图形介面的功能,他单纯是用在计算上面,因此我没有在
slave 上面安装图形介面的打算~至于 Master 则安装了 KDE 这个咚咚喔!好了,Linux
的安装相信大家应该都要很熟悉了,所以我就不再谈安装的详细步骤,仅提几个特别需要注意的地方啰:
-
Partition 方面:
因为我的硬碟实在是在蛮大的,并且在 Slave 上面也是 120 GB 的硬碟,如果不将
Slave 的硬碟使用的话,实在觉得很浪费,因此,一开始我就规划将四部主机的硬碟全部都以
NFS 分享到内部网络当中,而为了避免跟系统的文件放在一起,因此,我就将硬碟分割出除了必要的
partition 之外,其他的就挂载在 /disk1 这个目录当中,四部主机的 parition
都相同,分别是:
-
/ : 10
GB
-
/var : 5 GB
-
/tmp : 3 GB
-
Swap : 3 GB ( 因为我每部
Linux 主机上面都有 1.5 GB 的记忆体 )
-
/disk1: 96 GB
-
安装时选择的套件:
所有的主机都需要底下的套件安装(注:因为原本的笔记记录的很乱,所以如果找不到相同的字眼,那就是我写错啦!):
-
Administrattion Tools
-
Development Tools
-
Editors
-
Engineering and Scientific
-
FTP Server
-
Kernel Development
-
Network Servers
-
Server configuration Tools
-
Sound and vedio
-
System Tools
-
Text-based Internet
-
Windows File servers
不过, Master 需要额外再增加 X Window 方面的支援,例如 KDE 与 X-Window
System 这两个主要的套件要勾选喔!
系统安装大致上就是这些吧,如果有疏漏的,请未来在安装完毕之后,再以原本
Red Hat 9 的光碟来重新安装他吧!反正 Red Hat 系统都是以 rpm 来安装的,挺容易安装的喔!整个安装完毕后,还花不到几分钟呢!
-
防火墙
( 含 NAT 主机 ) 与网络设定
由于我们的 Cluster 主要是用在数值运算,因此,当然不需要对外开放网络服务啦!所以,最好就是以私有
IP 来进行网络的设定是比较好的!此外,最好还是要设定好防火墙的啦!我的网络参数预设是这样的:
-
Network/netmask:192.168.10.0/255.255.255.0
-
Master:(对外)140.116.xxx.yyy;(对内)192.168.10.30,
Gateway 为对外的 Gateway 喔!并且有设定 NAT 啊!
-
Slave:192.168.10.10, 192.168.10.20, 192.168.10.40
三部,Gateway 为 192.168.10.30
网络参数的各个文件是这样的:
-
各个主机的主机名称请修改:/etc/sysconfig/network
-
各个主机的网络卡设定项目请修改:/etc/sysconfig/network-scripts/ifcfg-eth0
-
各个主机的 DNS 查寻系统请修改:/etc/resolv.conf
-
各个主机的内部主机名称查寻系统请修改:/etc/hosts,我的
/etc/hosts 如下:
127.0.0.1
localhost localhost.localdomain
192.168.10.10
node1.cluster
192.168.10.20
node2.cluster
192.168.10.30
server.cluster
192.168.10.40
node4.cluster
而我的每部主机先将所有的网络服务都给他关掉去,仅剩下 SSH 这个网络协定存在而已~所以,我利用
Red Hat 提供的 ntsysv 这个指令来选择开机时启动的项目有:
-
atd
-
crond
-
iptables
-
keytable
-
network
-
random
-
sshd
-
syslogd
-
xinetd
至于防火墙系统的规划上面,由于 Master 主机 (192.168.10.30) 具有 NAT
的功能,所以必须要修改一下他的防火墙机制,因此,就有两个不同的防火墙机制
scripts 啰!另外,由于担心外来的入侵攻击,因此,在这个 Cluster 的系统当中,我的
iptables 防火墙机制是使用‘MAC(网络卡卡号)’来做为设定的基准,而不是使用
IP 啊!为什么呢?因为反正我仅允许我自己同网络内的几部电脑连进来而已,当然没有必要针对
IP 啊!所以啰,就必须要收集四部主机的网络卡来允许他进入啰。此外,由于我可能并不在
Cluster 前面操作,因此会启用一两部主机的网络卡卡号,好让他能够进入 Cluster
呦!底下就将我的防火墙机制给他列出来一下:
-
Master:
#!/bin/bash
# This program
is for iptables' rules
# VBird 2003/05/02
#
# 0. PATH and
modules
PATH=/sbin:/bin:/usr/sbin:/usr/bin
export
PATH
modprobe
ip_tables
modprobe
iptable_nat
modprobe
ip_nat_ftp
modprobe
ip_nat_irc
modprobe
ip_conntrack
modprobe
ip_conntrack_ftp
modprobe
ip_conntrack_irc
#
# 1. clear
the rules and make the policys
iptables
-F
iptables
-X
iptables
-Z
iptables
-F -t nat
iptables
-X -t nat
iptables
-Z -t nat
iptables
-P INPUT DROP
iptables
-P OUTPUT ACCEPT
iptables
-P FORWARD ACCEPT
iptables
-t nat -P PREROUTING ACCEPT
iptables
-t nat -P POSTROUTING ACCEPT
iptables
-t nat -P OUTPUT ACCEPT
#
# 2. NAT services
echo
"1" > /proc/sys/net/ipv4/ip_forward
iptables
-t nat -A POSTROUTING -s 192.168.10.0/24 -o eth1 -j MASQUERADE
#
# 3. Trust
network and conditions
iptables
-A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables
-A INPUT -i lo -j ACCEPT
iptables
-A INPUT -m mac --mac-source XX:YY:ZZ:WW:QQ:PP
-j ACCEPT
# 上面这一行就是网络卡的卡号啦! |
-
Slave:
Slave 的防火墙机制跟 Master 几乎一模一样,只是因为在内部啊,所以不需要启动
NAT 的服务即可!上面的给改一改先~
好啦!网络的设定与防火墙就到这里为止,要记得喔,你的网络必须要已经能够正确的启动了!如果还是无法启动网络,或者是防火墙机制还是有问题,那么对外的那个网络卡的网络线还是先给他拔掉吧!比较安全一些些的啦!等到都设定妥当,尤其是防火墙,然后才来启动他吧!
-
NFS 搭建规划
由于我这里预计要设定 NIS ,并且每部主机的 /disk1 都要分享出去,因此,每部主机都必须要开放
NFS 的服务喔!并且,每一台主机的设定都可以相同呐!这样比较容易来设定啰~此外,比较不一样的地方在于
Master 这一台,由于我的 Cluster 所有的帐号都在 NIS 的管制之中,因此,我将
Master 的 /home 也分享出来,并且每部 Slave 主机都挂载 Master 的 /home 才成!
这个 NFS 在 Cluster 当中是相当重要的,为什么呢?因为我们不是在四部主机上面工作吗,而这四部主机会去读取的‘资料’其实都是‘在本机上面可以看的到的’资料才行,这还包括底下我们会持续介绍的
mpich 这个软件的函式库呢!也就是说:‘在 Cluster 里面,所有的机器会使用到的资料必须都在相同的目录当中!’所以,这就是为什么我们要对
/home 进行分享,以及进行 NIS 的设定了!此外,因为我的 Server 这部 Master
机器分享出去的目录中,已经含有 /disk1 这个 partition,此外,还通通将他挂载在
/cluster/server 底下,因此,可以建议:‘未来在安装所有的
Cluster 需要的套件资料时,例如 Compiler 以及 MPICH 等等,都可以安装到 /cluster/server
这个目录底下,以使所有的主机都能够使用同一个 partition 来源的资料喔!’
设定程序:
1.
启动 portmap 并且设定开机启动:
[root @server
root]# /etc/rc.d/init.d/portmap start
[root @server
root]# chkconfig --level 35 portmap on
2. 设定 NFS
分享出去:
[root @server
root]# vi /etc/exports
/home
192.168.10.0/24(rw,async,no_root_squash)
/disk1 192.168.10.0/24(rw,async,no_root_squash)
[root @server
root]# exportfs -rv
[root @server
root]# /etc/rc.d/init.d/nfs start
[root @server
root]# chkconfig --level 35 nfs on
3. 设定预计的挂载点:
[root @server
root]# mkdir -p /cluster/node1
[root @server
root]# mkdir -p /cluster/node2
[root @server
root]# mkdir -p /cluster/node4
[root @server
root]# mkdir -p /cluster/server |
-
Slave:
1.
启动 portmap 并且设定开机启动:
[root @node1
root]# /etc/rc.d/init.d/portmap start
[root @node1
root]# chkconfig --level 35 portmap on
2. 设定 NFS
分享出去:
[root @node1
root]# vi /etc/exports
/disk1 192.168.10.0/24(rw,async,no_root_squash)
[root @node1
root]# exportfs -rv
[root @node1
root]# /etc/rc.d/init.d/nfs start
[root @node1
root]# chkconfig --level 35 nfs on
3. 设定预计的挂载点:
[root @node1
root]# mkdir -p /cluster/node1
[root @node1
root]# mkdir -p /cluster/node2
[root @node1
root]# mkdir -p /cluster/node4
[root @node1
root]# mkdir -p /cluster/server |
挂载程序:
-
Master:
将底下这些指令测试执行一下,如果成功后,将指令写入 /etc/rc.d/rc.local
当中
[root
@server root]# mount -t nfs -o bg,intr server.cluster:/disk1
/cluster/server
[root @server
root]# mount -t nfs -o bg,intr node1.cluster:/disk1
/cluster/node1
[root @server
root]# mount -t nfs -o bg,intr node2.cluster:/disk1
/cluster/node2
[root @server
root]# mount -t nfs -o bg,intr node4.cluster:/disk1
/cluster/node4 |
将底下这些指令测试执行一下,如果成功后,将指令写入 /etc/rc.d/rc.local
当中
[root
@node1 root]# mount -t nfs
server.cluster:/home /home
[root @node1
root]# mount -t nfs -o bg,intr server.cluster:/disk1
/cluster/server
[root @node1
root]# mount -t nfs -o bg,intr node1.cluster:/disk1
/cluster/node1
[root @node1
root]# mount -t nfs -o bg,intr node2.cluster:/disk1
/cluster/node2
[root @node1
root]# mount -t nfs -o bg,intr node4.cluster:/disk1
/cluster/node4 |
呵呵!这样就设定成功了!我们每一台主机‘看起来’就好像有 400 GB 的硬碟空间啊!可怕了吧!
^_^
-
NIS 搭建规划
NIS 的设定也是很简单,不过主要还是需要分为 NIS Server 与 NIS Client
两部份来设定的!请注意,在设定之前,就已经要将 NFS 搞定喔!这些流程都是有一定程度的相关性的呢!
-
Master:
在 Master 上面需要进行的工作很多喔!首先,一定要修改 ypserv.conf 以及其他相关的文件的呐!
1.
启动 time 与 time-udp 这两个预先要启动的 daemon
[root @server
root]# chkconfig --level 35 time on
[root @server
root]# chkconfig --level 35 time-upd on
[root @server
root]# /etc/rc.d/init.d/xinetd restart
2. 建立 NIS
的领域名称 (我这里是设定为 cluster ):
[root @server
root]# nisdomainname cluster
[root @server
root]# echo "/bin/nisdomainname cluster" >>
/etc/rc.d/rc.local
[root @server
root]# echo "NISDOMAIN=cluster" >> vi /etc/sysconfig/network
3. 建立 NIS
设定档:
[root @server
root]# vi /etc/ypserv.conf
(在这个文件内增加三行即可)
127.0.0.0/255.255.255.0
: * : * : none
192.168.10.0/255.255.255.0:
* : * : none
*
: * : * : deny
[root @server
root]# touch /etc/netgroup
4. 启动 NIS:
[root @server
root]# /etc/rc.d/init.d/ypserv
start
[root @server
root]# /etc/rc.d/init.d/yppasswdd start
[root @server
root]# chkconfig --level 35 ypserv on
[root @server
root]# chkconfig --level 35 yppasswdd on
5. 制作资料库:(每次有更动使用者资讯时,就必须要进行这个步骤!)
[root @server
root]# /usr/lib/yp/ypinit -m
[root @server
root]# chkconfig --level 35 ypserv on
[root @server
root]# chkconfig --level 35 yppasswdd on |
-
Slave:
至于 NIS Client 则是需要设定 yp.conf 这个文件呢!
1.
建立 NIS 的领域名称 (我这里是设定为 cluster ):
[root @node1
root]# nisdomainname cluster
[root @node1
root]# echo "/bin/nisdomainname cluster" >>
/etc/rc.d/rc.local
[root @node1
root]# echo "NISDOMAIN=cluster" >> vi /etc/sysconfig/network
2. 建立 NIS
查寻的主机名称:
[root @node1
root]# vi /etc/yp.conf
domain cluster
ypserver server.cluster
3. 修改密码验证方式:
[root @node1
root]# vi /etc/passwd
(在这个文件的最底下新增如下一行)
+::::::
[root @node1
root]# vi /etc/nsswitch.conf
passwd:
files nis nisplus
shadow:
files nis nisplus
group:
files nis nisplus
hosts:
files nis dns
4. 启动 NIS:
[root @server
root]# /etc/rc.d/init.d/ypbind
start
[root @server
root]# chkconfig --level 35 ypbind on |
呵呵!不啰唆!马上就设定妥当啦!
-
RSH 设定
这个 RSH 已经提过了,主要的功能是提供 Master 可以使用 R 指令(如 rsh,
rlogin, rcp 等等)来进行 slave 端主机的操控的!所以啦, RSH daemon 主要是在
slave 机器上面搭建的喔!与 Master 就无关啦!Master 只要能够执行 R command
即可!虽然是如此,不过,在我的测试当中,最好 Master 也启动 RSH 比较好一些些啰!在底下的设定当中,我们假设
Server 上面的所有使用者都可以使用 R command 呢!设定的方法很简单啊!
-
Slave & Master:
底下的设定在 Master 与 Slave 上面都需要动作喔!设定一样即可!
1.
启动 RSH 啰!
[root @node1
root]# chkconfig --level 35 rsh on
[root @node1
root]# /etc/rc.d/init.d/xinetd restart
2. 编辑可使用
R command 的主机设定档:
[root @node1
root]# vi /etc/hosts.equiv
server.cluster
+ |
特别注意,由于 RSH 预设就是不支援 root 使用 R command ,所以您必须要到
master 上面去,并以一般身份使用者进行 R command 的测试才行喔!不要直接以
root 工作,会无法成功的啦!(显示 permission deny 的啦!)
-
Master:
由于 RSH Server 上面的设定中,您的 User 家目录必须要存在一个名为 .rhosts
的文件,原本我的 Server 上面就有一个名为 test 的使用者,而并且为了让我未来新建立的使用者都能够使用
R command ,所以我在 Master 这部机器上面做了这样的动作喔:
[root
@server root]# vi /home/test/.rhosts
server.cluster
[root @server
root]# vi /etc/skel/.rhosts
server.cluster
[root @server
root]# chmod 644 /etc/skel/.rhosts |
这样就妥当的设定好了 RSH 啰!
-
安装 Fortran
90 的编译程序 PGI pgf90 ( PS. server version )
我由 PGI 的官方网站下载了最新的 PGI Server 套件,请特别留意的是,由于
PGI 有两种模式,一种是工作站(Workstation)一种则是服务器(Server)模式,其中,工作站仅能提供单一主机来操作,无法进行
Cluster 的功能的!因此,请务必要下载 Server 的版本,并且是支援
Linux 版本的喔!不要搞混了! PGI Fortran Server version 的下载网址在这个地方:http://www.pgroup.com/downloads.htm,请自行下载吧!比较需要留意的是,从上面这个网站下载的版本仅是分享软件的版本,您安装之后可以具有
15 天的免费使用期限,超过期限之后,又需要重新安装一次,很是麻烦的啦!如果您的
Cluster 是用来进行学术研究的,那么在测试完成之后,可能需要去他的网站注册,这个注册的费用差异可就很大了~因为未来我的
Cluster 需要一直不断的运作,因此是需要去注册的啦!并且,我只会用到 Fortran
这个编译器,因此,我就直接使用 PGIHPF 这个版本来测试安装而已,而不是使用全部
( 含 PGI Fortran 与 C ) 的版本喔!因为注册的价差差了两~三万台币啊!安装
Fortran 真是很简单的啦!假设您将 linux86-HPF.tar.gz 放置在 /root/software
底下,则:(注:以下的动作仅只要在 Master 上面进行即可喔!)
1.
建立 pgi fortran 在 /cluster/server/program/pgi 底下:
[root @server
root]# cd /usr/local/src
[root @server
src]# mkdir pgi-fortran; cd pgi-fortran
[root @server
pgi-fortran]# tar -zxvf /root/software/linux86-HPF.tar.gz
[root @server
pgi-fortran]# ./install
接下来会有一些问题,请依序回答您的问题喔!
至于授权嘛!请建立吧!
最重要的地方,是在第三个问题,他会问你要安装的目录,请选择
/cluster/server/program/pgi
2. 修改个人参数:由于
RSH 不以 root 工作,所以我以使用者 test 来测试:
[root @serer
root]# vi /home/test/.bashrc
# 加入这几行关于
PGI 的咚咚:
PGI=/cluster/server/program/pgi
export PGI
PATH=$PGI/linux86/bin:$PATH
3. 设定查寻路径:
[root @server
root]# vi /etc/man.config
# 加入这一行:
MANPATH /cluster/server/program/pgi/man |
这样就好了吗?!没错!确实是这样就完成了!很是简单吧! ^_^要注意的是:
-
记得 pgf90 必须要让所有的 node 都能够读的到,所以一定要安装在 Server 的分享出去的目录当中,我这里的例子就是安装在
/cluster/server/program/gpi 这个目录当中啰!
-
执行档要能够执行,当然是必须要让目录在 PATH 这个变数底下,而我的 pgf90
是在 /cluster/server/program/pgi/linux86/bin 底下,所以,您的 PATH 必须要含有这个目录才行!
大概就是如此啰!
-
安装 MPICH
前面我们提过了,安装 MPICH 是平行运算里面最重要的一项工作了!因为我们就是靠他来帮我们达成运作的啊!那么怎么来安装呢?又是简单得不得了啊!首先,请先下载
mpich 吧!下载的网址在底下,我是以 mpich 1.2.5-1a 来测试的喔!
假设您将 mpich 下载在 /root/software 里面,并且预计要安装到 /cluster/server/program/mpich
当中,而且仅安装 Fortran 而已的话,可以这样做:
1.
建立 mpich 在 /cluster/server/program/mpich 底下:
[root @server
root]# cd /usr/local/src
[root @server
src]# tar -zxvf /root/software/mpich.tar.gz
[root @server
src]# cd mpich-1.2.5
[root @server
mpich-1.2.5]# ./configure --enable-debug \
>
-fc=pgf77 -f90=pgf90 \
>
--prefix=/cluster/server/program/mpich
[root @server
mpich-1.2.5]# make && make install
2. 建立可以利用的主机状态:
[root @server
mpich-1.2.5]# cd /cluster/server/program/mpich/share
[root @server
share]# vi machines.LINUX
node1.cluster:2
node2.cluster:2
node4.cluster:2
server.cluster:2
# 这个文件当中,格式为
<主机名称>:<主机的 CPU 个数>
3. 建立需要的变数:(又是以
test 为准喔!)
[root @server
root]# vi /home/test/.bashrc
# 加入这一些资料:
PATH=$PATH:/cluster/server/program/mpich/bin
export PATH
MPI_HOME=/cluster/server/program/mpich
MPI_ARCH=$MPI_HOME/bin/tarch
export MPI_ARCH
MPI_HOME
[root @server
root]# vi /etc/man.config
# 加入这一行:
MANPATH /cluster/server/program/mpich/man |
呵呵!这样就已经完成了 MPICH 的安装与设定了!就跟你说很简单吧!但是呢,要测试可就得需要特别留意了,因为
root 预设是不许使用 RSH 的,所以测试一定要使用一般身份的使用者,这里我以
test 这个人做为测试的使用者喔!所以,请以 test 的身份登入主机,并且,这个
test 必须要在所有的主机上面都可以被查询的到才行(请参考 NIS 的设定喔!)。
[test
@server test]$ cp -r /cluster/server/program/mpich/examples/
.
[test @server
test]$ cd examples
[test @server
examples]$ make pi3f90
[test @server
examples]$ mpirun -np 8 pi3f90
# 上面那个
-np 后面接的就是使用 CPU 的个数啦!因为我有 8 个 node ,
# 所以当然就以最大的
CPU 个数来测试看看,如果要看到底 CPU 有没有启动的话,
# 可以先登入各个
slave 的主机,然后执行‘ top -d 1 ’来观察 CPU 的使用率,
# 再执行上面这个程序,就能够知道
CPU 有没有运作了! ^_^ |
呵呵!没想到 PGI 的试用版本就能够提供多颗 CPU 的 Cluster 运作,真是给他很高兴!这样既然可以测试成功了,自然就可以去向
PGI 的官方网站注册了!注册费用不低,但是挺值得的啊!
其他主机相关设定:
重点回顾
-
Cluster 可以是平行计算的一种,主要除了双 CPU 系统外,也可以用在多主机架构下的一种增快数值计算的方式;
-
平行计算的 Cluster 主要是藉由主从的架构去运行的,其主要的设定都在
Master 上面设定的, Slave 主要是计算功能而已,
-
Cluster 上面相当重要的地方在于 NFS 的设定,因为 Master/Slaves
都需要读取同样的资料,所以 NFS 分享的文件资料就极其重要了;
-
除了 NFS 之外,还需要 MPI 这个平行计算的函式库之安装,有了
MPI ,Cluster 才能真的运作起来;
-
在 Cluster 当中,所有的主机之指令的沟通主要亦经过
RSH 的运作;
参考资源
简易
Cluster 搭建
2003/05/12:第一次完成日期!
2003/05/20:加入了
X
Server/Client 的架构!
|
|
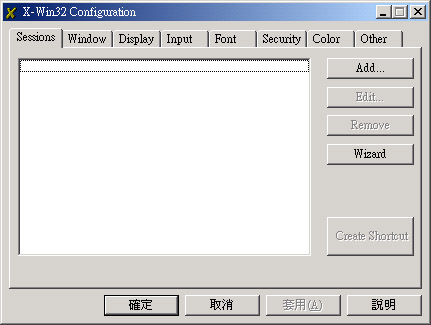
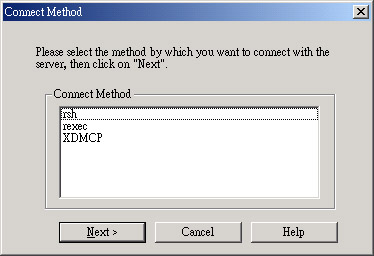
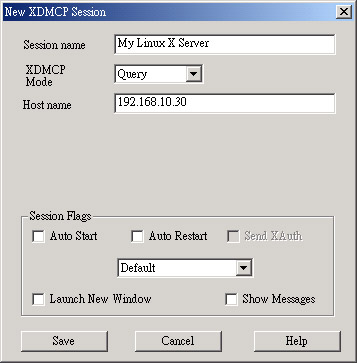
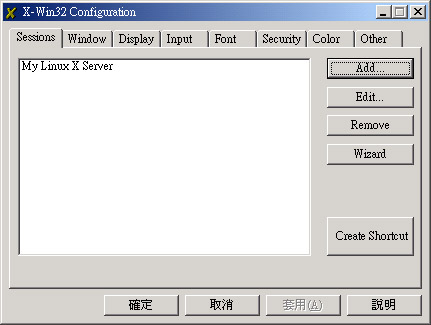
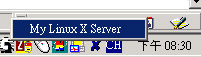 ) 按一下 X 之后,就会出现刚刚我们建立的 My Linux X Server 这个选项,给他选择下去的啦,呵呵!就会出现啰:
) 按一下 X 之后,就会出现刚刚我们建立的 My Linux X Server 这个选项,给他选择下去的啦,呵呵!就会出现啰: