今天遇到给sphinx做备份节点的时候遇到点问题,发现以前主节点(三个实例三个库的那种)的server id 超过了2^23-1了,但是并没有报错,查了一下可能是版本比较旧了,并没有报这个错误,但是根据bin-log日志检查发现serverid被转化为其他的一
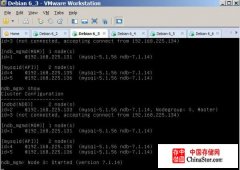
今天遇到给sphinx做备份节点的时候遇到点问题,发现以前主节点(三个实例三个库的那种)的server id 超过了2^23-1 了,但是并没有报错,查了一下可能是版本比较旧了,并没有报这个错误,但是根据bin-log日志检查发现server id被转化为其他的一个值了,所以可以正常运行。后来在测试机上我发现一个问题如果server-id设置超长的话转化的新的server-id会产生重复的值。便引发了思考,会不会一主多从架构中从库如果server-id重复的话,数据是否mess. 按照这种思想我做了一下实验,简单的架构1主2从,2个从库server-id一致,主库插入10000条数据,然后show slave status 从库,发现 IO thread 会一会开一会关,但是最后这10000条数据也都同步到两个从库了。数据是正常的。所以可以草率的做个结论就是主从架构(master-slave)中如果从库server-id重复,数据不会mess,但是会影响向主库取得数据的效率,也就是会产生延迟,同时由于每次IO thread 重启的话都会造成relay-log日志刷新,所谓刷新就是频繁的打开关闭relay-log,打开新的relay-log存放io thread取得的数据,关闭删除sql thread已经应用完成的relay-log。默认relay-log大小是按照max_relay_log_size这个参数切换的,如果该参数没有设置的话,按照max_bin_log_size设置。也就是说满足这个最大值才发生日志切换了。现在这种情况就会造成产生大量size比较小得relay-log文件。形象点得话就是如下图所示:
Let us demonstrate it.Slave1 and Slave2 have the same server-id.
1. Slave1 connects to master.
2. Slave2 connects to master.
Slave1 has the same server-id, so it is killed.
3. Slave1 tries to connect to master automatically.
Slave1 connects successful.
Slave2 is killed.
4. Slave2 tries to connect to master again.
Slave2 connects successful.
Slave1 is killed.
5. ......
......
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。