重复数据删除(data de-duplication)是一种可自动搜索重复数据,将相同的数据只保留唯一的一个副本,并使用指向单一副本的指针替换掉其它重复副本,以达到消除数据冗余、降低存储容量需求的存储技术。
重复数据删除技术的研究现状
重复数据删除(data de-duplication) 也称为智能压缩(intelligent compression) 或单一实例存储(single-instance storage ),是一种可自动搜索重复数据,将相同的数据只保留唯一的一个副本,并使用指向单一副本的指针替换掉其它重复副本,以达到消除数据冗余、降低存储容量需求的存储技术。
常见的重复数据删除技术有两种情况:
(1)文件复制消除技术,
它可以识别两个文件名不同但是内容完全相同的文件,或者不同目录下相同的文件,可以避免相同文件的多次存储;
(2)数据块冗余消除技术,
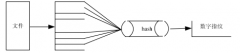
它比文件复制消除的存储效率更高,它可以在文件中搜索相同的数据块,将相同的块保存为一个唯一的副本。目前重复数据删除技术主要有基于文件级、散列(hash)和内容识别三种实现方式。
重复数据删除是一种独特存储技术,分析师认为它可能是存储行业最重要的一项新兴技术,将改写存储行业的经济规则:借助于重复数据删除技术,使得实际存档的数据呈几何级别递减,用户的存档数据所占用的空间将会缩减为现在的 5%,从而大幅削减存储成本。
重复数据删除效率来源于文件的相似性,但重复数据删除技术并不要求所有资料都采用某个独特的算法和方案,而是提供一个或多个冗余数据消除的技术框架,具体技术实现一般采用多种算法结合使用,实现逐步特征匹配过程。即:首先匹配相同的文件,其次匹配高相似性的文件,最后匹配有某些相似的文件。因此,重复数据删除技术可使各种不同类型的数据存储系统受益。
目前,重复数据删除技术并没有成为一个独立存储产品,而是作为存储系统中的一个新的重要功能。它的主要技术优势体现在以下几个方面:
首先,重复数据删除技术为数据保护领域带来了革命性的突破,有效地改善了基于磁盘数据保护的成本效益。
因为在传统数据保护中是无法实现重复数据删除的,存储系统往往是采用廉价的磁带库作为备份设备,磁带备份在备份窗口、恢复速度方面难以满足用户的需求。现在,基于盘的数据保护方案例如 VTL(虚拟磁带库)已经被广泛采用,并且在未来还会继续增长。备份到 VTL 或其他基于磁盘的备份已经缩短了备份窗口,改善了备份和恢复能力;但由于数据量的不断增加,我们所要备份的数据越来越多,面临容量膨胀的压力,而重复数据删除技术的出现,则为优化或者最小化存储容量提供了一种有效的解决方法。
其次,重复数据删除技术对归档存储也非常重要。
由于参考数据的数量不断增长,而法规遵从要求数据在线保留的时间更长,并且由于高性能需求需要采用磁盘进行归档,因此,企业一旦真正开始进行数据的归档存储就面临成本问题。理想的归档存储系统应能满足长期保存归档数据的需求,并且总拥有成本也要低于生产环境。重复数据删除技术通过消除数据冗余来实现高效率的归档存储,从而实现了最低的成本开销。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。