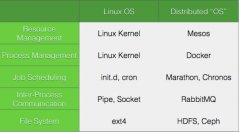
美国加州大学伯克利分校的AMPLab开发的分布式文件系统Tachyon充分使用内存和文件对象之间的世代(lineage)信息,号称最高比HDFS吞吐量高300倍。
Hadoop里的HDFS已经成为大数据的核心基础设施,觉得它还不够快?近日,美国加州大学伯克利分校的AMPLab开发的分布式文件系统Tachyon受到了广泛关注。
Tachyon(英文超光子的意思,指假想的比光还快的粒子)的特点是充分使用内存和文件对象之间的世代(lineage)信息,因此速度很快,项目自己号称最高比HDFS吞吐量高300倍。
实际上,不仅仅是要用Tachyon试图取代HDFS,AMPLab已经完全重建了一套类似Hadoop的大数据平台,“没有最快,只有更快”。AMPLab在大数据领域最知名的产品是Spark,它是一个内存中并行处理的框架,Spark的创造者声称:使用Shark运行并行处理Job速度要比MapReduce快100倍。又因为Spark是在内存运行,所以Shark可与Druid或者SAP's HANA系统一较高下。Spark也为ClearStory下一代分析和可视化服务提供处理引擎。如果你喜欢用Hive作为Hadoop的数据仓库,那么你一定会喜欢Shark,因为它代表了“Hive on Spark”。
AMPLab的最新目标就是Hadoop分布式文件系统(HDFS),不过HDFS在可用性和速度方面一直受人诟病,所以AMPLab创建了Tachyon( 在High Scalability上非常夺目,引起了Derrick Harris的注意),“Tachyon是一个高容错的分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享,类似Spark和 MapReduce。通过利用lineage信息,积极地使用内存,Tachyon的吞吐量要比HDFS高300多倍。Tachyon都是在内存中处理缓存文件,并且让不同的 Jobs/Queries以及框架都能内存的速度来访问缓存文件”。
当然,AMPLab并不是第一个对HDFS提出质疑的组织,同时也有很多商业版本可供选择,像Quantcast就自己开发了开源文件系统,声称其在运行大规模文件系统时速度更快、更高效。

诚然,AMPLab所做的工作就是打破现有商业软件的瓶颈限制。如果碰巧破坏了现状,那么就顺其自然吧!不过,对于用户来说,AMPLab只是为那些寻找合适工具的人员提供了一种新的选择,AMPLab的合作伙伴和赞助商包括谷歌,Facebook,微软和亚马逊网络服务,它们当然非常乐意看到这些新技术,如果很有必要的话。
AMPLab的其他项目包括PIQL,类似于一种基于键/值存储的SQL查询语言;MLBase,基于分布式系统的机器学习系统;Akaros,一个多核和大型SMP系统的操作系统;Sparrow,一个低延迟计算集群调度系统。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。