半自动化搭建DataGuard,安装前的配置占用70~80%的时间,所以半自动化的目标主要是配置,就是能简化配置,简化安装。
本次分享将分为以下几部分:
- 半自动化搭建DataGuard
- 用不用DGBroker
- 几个实用场景演练
- 与时俱进:Oracle12c DataGuard改进
- 诊断案例:备库批量查询失败的案例分析
- 数据迁移中巧用DataGuard
一、半自动化搭建DataGuard
说实话,单纯搭建DataGuard的工作现在已经没什么技术含量了,而且手工搭建耗时,很可能会有很多的问题,所以我有个想法就是改进,也就是把它半自动化。
大体来说,搭建DataGuard有下面的一些问题:
- 搭建DataGuard看似工作量巨大
- 配置繁多(主库端,备库端)
- 问题琐碎(如果配置不当,很容易陷入各种问题漩涡)
- 规范化,标准化混乱,备库各有各的特点
- 主机名混乱
- Db_unique_name混乱
- 数据库参数不统一
- 主备的listener.ora,tnsnames.ora中的host有的用IP,有的用主机名
- Profile文件不统一
为什么是半自动化,初衷如下:
- 就是为了安全
- 主库就是主库,不要轻视任何微小的操作
- 主库不规范的地方改动要谨慎
- 备库不规范的地方改动要到位
半自动化的主要目标和套路如下:
安装前的配置占用70~80%的时间,所以半自动化的目标主要是配置,就是能简化配置,简化安装。
搭建备库的两种常用方式:
基于备库搭建备库
rman备份->restore->recover(10g)
基于duplicate的方式
在线搭建(11g)
说到这里有些羞愧,我自己在内部目前是使用这种方式,效果还不错,但是因为环境的差异,后期的脚本没有流程化,容错校验也不多,所以一直没有开放出来,近期会开放出来,大家保持关注吧。
二、用不用DGBroker
DGBroker是Oracle为DataGuard维护提供的一个很不错的工具,从我的实际使用来看,早期的版本中似乎大家都还是存在一定的思维定式,认为手工维护已经足够了。完全可以脱离开这些工具来直观的使用命令行的方式来维护,这个观点没错,不过存在一主多备的环境,环境较为复杂的情况,这样一个能够让你更轻松的工具,如果不用实在是太可惜了。
DGBroker在数据库端需要启用一个后台进程DMON来维护,这个后台进程启动,需要设置dg_broker_start为true即可,如果要停止,只需要设置这个参数为false即可。从系统资源的角度来考虑,那几乎可以忽略不计。
从搭建的便捷性上来看,DataGuard的搭建有了DGBroker已经几乎没有了技术含量。
当然DGBroker毕竟只是一个工具而已,如果不懂DataGuard的基本原理,不熟悉手工维护,那么还是先把那个坑踩平了再来玩这个工具。工具永远就是一个媒介。好与不好,明心自鉴,过度依赖工具与完全脱离工具,都是两个不可取的极端。
我是从手工的管理方式过渡到DGBroker的,上了这条船,其实发现还是值得的,所以有不少朋友也问我是否应该在生产环境中使用DGBroker,我的回答是放心用吧。上面我要讲的半自动化搭建主要就是希望用DGBroker的方式来完成最后的配置。
三、几个实用场景演练
1.如何演练Failover
有一天看到有一个网友提了一个问题,描述很简短:测试DG时,主库不能宕机,如何测试failover?
其实这个需求从业务层面来说是合理的,一个数据量很大的核心数据库,如果需要做灾难演练,就希望在备库上做一下演练工作,而这个演练其实又不想影响到目前的主库,而且又希望能够尽可能模拟真实的情况,我想这样对于运维部门来说是最具有考核力度,而对于开发业务部门来说是最受欢迎的,因为他们什么都不需要改动。
而从技术角度来看,似乎有一些地方需要考量,如果备库Failover为主库,那么这个主库肯定是可以进行读写操作的,如果把它再切回备库,数据一致性怎么保证,怎么能保证是从上次的断点开始恢复。如果可以做,那真是一大福利。
我们先讲讲思路,还是闪回,但是闪回的玩法有一些差别,和reinstate的方式有一些区别。假设是一主一备的环境,备库开启了闪回数据库功能
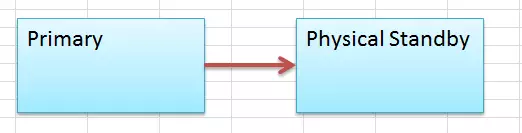
我们不动原来的主库,把备库Failover为主库。

然后这个时候Failover的主库可读可写,当然最后还是要切换回备库接收归档,可以使用闪回,同时还需要切换角色,这个地方需要好好琢磨一番该怎么处理。

然后我们需要切换为备库,切换的命令就是关键,不是使用switchover的方式。
SQL> alter database convert to physical standby;
再举一个更极端的案例,做数据库的切换Switchover,然后发现了问题,需要回退,恢复到原来更早的状态,这个能不能办到,有了闪回,照样可以。
大体的思路就是下面的形式:
首先是一个主备库的环境:
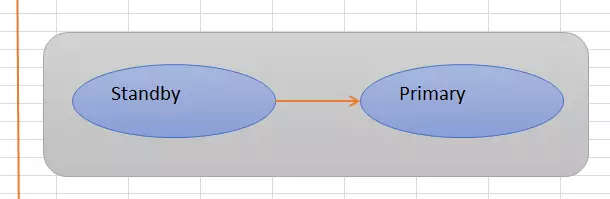
switchover是计划内的任务,就是主切备,备切主。
这个时候发现切换出现了问题,我们需要紧急回退,需要回退到切换前的状态,要知道此时的主库已经不是原来的主库,备库也不是原来的备库了。闪回是否依旧可行,备库是否可以依旧选择一个新的断点可以重新同步?
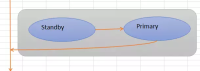
实际上这种方案还是可行的,但是建议是可以作为PLAN B来用,当然希望最好不要有这种情况发生。
有一套一主两备的10gR2环境,一个异机备库一直在READ ONLY状态,也就意味着数据库在打开之后一直没有应用归档,然后在某一天发现时,已经延迟了好几个月。无论怎样,还得庆幸发现了这个问题。
目前来看一种行之有效的方法就是重搭备库,但是这种修复方式需要大量的磁盘空间,而且需要恢复的时间较长,怎么改进呢,可以考虑通过基于SCN的增量备份来跳归档恢复。目前的环境是一主两备,再怎么改进呢,我们可以基于备库1来完成基于SCN的增量备份,在备库2完成恢复,对于主库几乎是完全透明,无影响的。
整个示意图如下,通过在Standby1上面基于SCN导出增量备份,拷贝到备库2上去恢复,最后再和主库汇合即可。
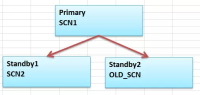
里面的核心用法就是增量备份恢复,说白了好像就那么回事,不过对于工作有帮助就行。
四、与时俱进:Oracle 12c Data Guard改进
Oracle的Data Guard技术在11g中有了Active Data Guard,就产生了很多的技术解决方案,比如读写分离,多活的技术支撑等,客户对于这个特性的喜爱程度很大程度上驱动了数据库的升级。
个人的体验,12c里面的改进有两个亮点,一个就是Far Sync,另外一个就是validate。
先说说Far Sync。以下是来自官方博客提供的一张图,看起来很威武霸气。
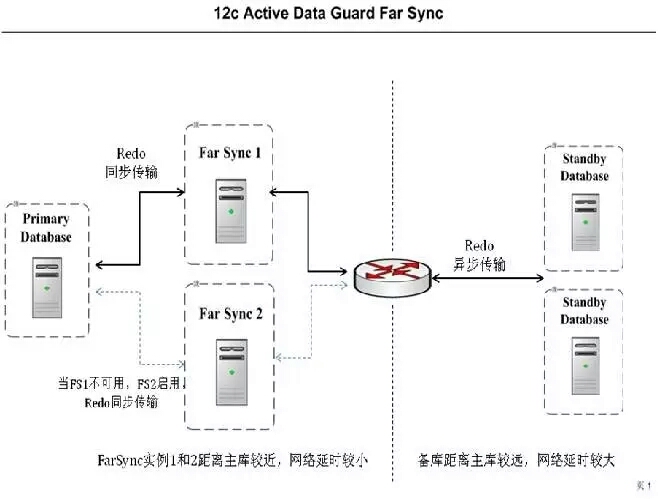
这个Far Sync到底是个什么东东,主要就是为了解决远距离的数据传输延迟,而在中间节点创建的一个虚实例,这个实例很特别,只有参数文件,密码文件和控制文件,而且需要特别强调的是没有数据文件。
当然这个特性是一个补充,你如果使用原本的Active Data Guard也全然没有问题。而这个特性可以通过中间节点来过渡,达到了官方所宣称的0数据丢失。
这个特性是不是非常牛叉呢,其实如果大家了解Data Guard的一些知识,本身备库的RFS可以在不存在数据文件的情况下,在mount状态下依然接受归档。
另外我们说说Cascade standby,在一主多备的环境中,当standby与primary的距离较远需要通过WAN来传输Redo时,为减少传输过程中对primary的压力及网络带宽的占用,仅让其中的一个standby从primary直接接收redo。
两者的结合和改进,就是Far Sync了,所以我没有说是一个技术上很大的一个创新,但是却能够给实际工作带来了不少的实惠。
如果已经有了Active Data Guard的环境,启用Far Sync那就很简单了。
下面是一个典型的DG配置情况,使用了DG Broker来统一配置管理。主库是testdb,备库是testdb2。
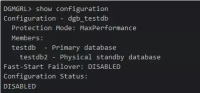
需要特别强调的是,Far Sync的添加一个关键就是控制文件,这个和备库控制文件有所区别。
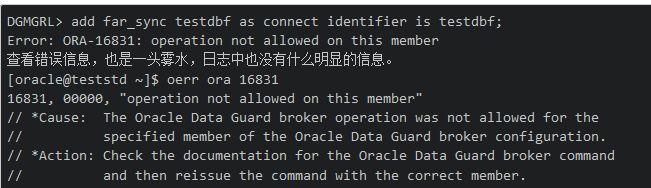
我刚开始玩的时候大意了,结果因为这个问题给折腾了不少时间。需引以为戒。
正确的姿势是在主库生成Far Sync的控制文件:

很重要的一个检查项就是检查v$database,输出全然不同。

再次添加Far Sync节点:
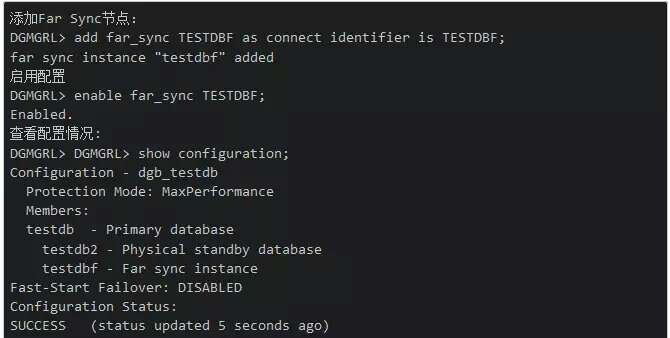
当然Far Sync实例本身的资源消耗很小,不需要再给它很高的配置,作为中继节点,保证网络的畅通更加重要。
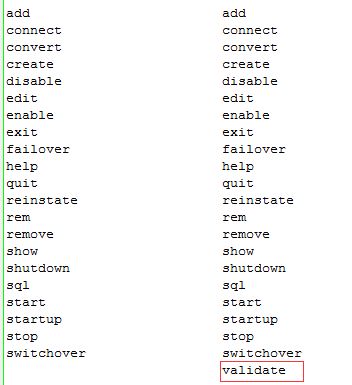
然后说说validate,这个改进比较贴心,如果需要switchover,是否可行,可以用validate来做一个检查。我对比了12c和11g中的DG Broker命令,唯一较大的差别就是validate,这个预检查还是一个很实用的改进。
五、诊断案例:备库批量查询失败的案例分析
然后给大家分享一个备库批量查询失败的案例,希望对大家分析问题有帮助。
数据库环境是10gR2,一主两备。其中一个备库上每天凌晨会开放一个窗口运行一些批量的查询,会通过crontab来调用DGBroker来在READ-ONLY和ONLINE之间切换。
但是有一天开发的同学突然找到我说,最近几天开始批量查询会频频报错,希望我帮忙查看一下。
错误日志如下,可以看到是一条查询语句。
[2016.03.0604:10:02.352]org.springframework.jdbc.UncategorizedSQLException:PreparedStatementCallback;uncategorizedSQLExceptionforSQL[selectbind_flagfromtest_billingwherecn_master=?];SQLstate[60000];errorcode[604];ORA-00604:erroroccurredatrecursiveSQLlevel1 [2016.03.0604:10:02.352]ORA-16000:databaseopenforread-onlyaccess [2016.03.0604:10:02.352];nestedexceptionisjava.sql.SQLException:ORA-00604:erroroccurredatrecursiveSQLlevel1 [2016.03.0604:10:02.352]ORA-16000:databaseopenforread-onlyaccess [2016.03.0604:10:02.352]
而从数据库层面没有任何的日志报错。
在备库想看看这个问题是否发生。于是根据日志中的语句使用DBA用户(属主是用户acc)查询了一下,发现没有任何问题。
selectbind_flagfromacc.test_billingwherecn_master=?语句可以顺利输出结果。
自己也尝试了dml的情况,错误信息也会有所不同。
SQL>updateacc.test_billingsetbind_flag=0wherecn_master='660078174';
updatetest_billingsetbind_flag=0wherecn_master='660078174'
*
ERRORatline1:
ORA-01552:cannotusesystemrollbacksegmentfornon-systemtablespace'ACC_DATA'
开始理一理思路,之前从来没有反馈过这个问题,而问题是在最近发生的。那么应用端是否在最近有什么变化呢,得到的反馈是在1月中下旬有一次变更,但是这都过去好久了,不足以佐证现在的问题。
而从数据库层面,如果存在问题,那看似只有bug的可能性了,但是查了MOS一圈,发现了几种可能的场景,但是都和目前的情况不符合,目前查到有两种场景,一种是略微复杂的查询,一种是带有dblink的查询。参考链接如下:
DblinkonPhysicalstandby-ORA-16000(DocID1296288.1)
ORA-16000WithASemanticQueryOnARead-onlyDatabase(DocID1928638.1)
目前的情况是这个语句非常简单,实在找不出来可能的原因了。
开发的同事也催的比较紧,但是感觉从数据库层面得到的信息着实有限。无奈之下,开启了手工debug方式。就从alert日志中的那个关于temp的报错开始分析。(在11g会有备库采样数据,这个问题解决就会容易很多了)
第二天通过日志看到应用运行之后,查看系统级,没有任何的抖动,数据库层面也可以看到应用是连接进来了。在反复确认调用的细节之后,我切换到指定的用户,再次尝试;然后再次运行这个报错的语句,终于得到了期望之中的报错。
SQL>selectbind_flagfromtest_billingwherecn_master='660078174';
selectbind_flagfromtest_billingwherecn_master='660078174'
*
ERRORatline1:
ORA-00604:erroroccurredatrecursiveSQLlevel1
ORA-16000:databaseopenforread-onlyaccess
采用owenr用户的方式来查看,就没有问题了。
SQL>selectbind_flagfromacc.test_billingwherecn_master='660078174';
BIND_FLAG
----------
689537
这个问题是怎么回事呢?
TEST_SHINK下的都是同义词,指向ACC这个owner用户,那么这个同义词有什么特别的呢。进一步查看,发现同义词test_billing状态是INVALID的。
而问题的修复就更简单了,在主库运行下面的SQL即可。
>selectcount(*)fromTEST_SHINK.TEST_BILLINGwherecn_master='660078174';
COUNT(*)
----------
1
因为这个用户应用只在备库使用,所以就导致了这个看起来奇怪的问题,看来都是事出有因,耐心一些,细致一些还是会有发现。对于这个问题更多的细节就不赘述了。
六、数据迁移中巧用DataGuard
DataGuard是数据迁移中一个很重要的方式,但是一大硬伤就是不可以直接升级数据库。可以简化来说,数据库升级的本质是升级数据字典,大批量数据库的情况下快速迁移数据,通过DataGuard来完成,然后导入数据字典信息其实也是一个不错的方式。
比如一套硬件环境是Solaris,Oracle10gR2单实例,数据量在800G左右。想迁移到另外一台服务器上。大体的需求如下:
- 借助这次维护的时机,能够把数据库升级至11g
- 升级的过程需要尽可能保留一个较短的时间窗口,计划在2个小时以内完成
- 有较好的解决方案去演练整个过程,多次总结,提高迁移的效率,保证质量
- 有完善的回退计划,能够支持回退场景下业务平滑过渡
- 目前对于跨平台没有明确的要求,可以继续使用Solaris,也可以考虑跨平台,但是影响范围要小。
这种情况下,就可以充分借助DataGuard来完成,我们可以在备库环境创建一个11g的数据库,db_name,字符集不变。

在备库端进行Switchover/Failover(具体选哪个,可以根据需求来定)后,导出传输表空间的元数据。这个时候对数据文件没有做任何操作,导出完成后,停掉备库端10g的数据库。
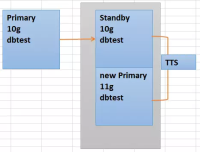
然后在备库导入传输表空间的元数据至新的11g库,数据文件路径依旧不变,因为传输表空间只传输表数据,对于存储过程,函数,视图,同义词,DB link,权限等都无法同步,所以可以在这个基础上选择性导出全库的指定schema的信息,导入目标库中,因为是DDL的导入,这个过程持续时间也会很快。
导入后就完成了基本的迁移,相比比Datapump,XTTS的传输同步数据的时长,这个过程可以控制在一个很短的时间内。
最后为个人的新书做一个宣传,《Oracle DBA工作笔记》是我个人笔记的精华选集,希望大家多多捧场,学习交流,共同进步。

作者:
建荣
搜狐畅游高级DBA
DBAplus社群联合发起人。现就职于搜狐畅游,OracleACE-A、YEP成员,超7年数据库开发和运维经验,擅长电信数据业务、数据库迁移和性能调优。
持Oracle10GOCP,OCM,MySQLOCP认证,《OracleDBA工作笔记》作者。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。