Tesla 超级计算机拥有 5,760 个 A100 GPU,目前这一数字已上升到 7,360 个 即增加了 1,600 个 GPU,增幅约 28%。
近日特斯拉为其内部的 AI 超级计算机增加了上千个GPU,大约一年前,Tesla 超级计算机拥有 5,760 个 A100 GPU,目前这一数字已上升到 7,360 个 即增加了 1,600 个 GPU,增幅约 28%。
根据特斯拉工程经理 表示,此次升级使该公司的 AI 系统成为全球 GPU 数量排名第 7 的超级计算机。

Nvidia A100 GPU是针对数据中心的强大 Ampere 架构解决方案,使用与 GeForce RTX 30 系列 GPU 相同的 GPU 架构,这是目前可用的最好的显卡之一。它配备了 80GB 的 HBM2e 内存,提供高达 2 TB/s 的带宽,并且功率高达 400W 。A100 的架构也进行了调整,以加速 AI、数据分析和高性能计算 (HPC) 应用程序中常见的任务。
Nvidia 历史上第一个使用 A100 的系统是Nvidia DGX A100,它包含通过六个 NVSwitch 连接的8个 A100 GPU,具有 4.8 TBps 的双向带宽,可实现高达 10 PetaOPS 的 INT8 性能、5 PFLOPS 的 FP16、2.5 TFLOPS 的 TF32 ,以及 156 TFLOPS 的 FP64 在单个节点中。
现在,特斯拉的 AI 超级计算机现在有 7,360 个。Tesla 尚未公开对其 AI 超级计算机进行基准测试,但配备类似 GPU 的 NERSC Perlmutter 拥有 6,144 个 Nvidia A100 GPU,可达到 70.87 Linpack petaflops。使用此数据和其他 A100 GPU 超级计算机的数据作为性能参考点,估计 Tesla AI 超级计算机能够实现大约 100 Linpack petaflops。
特斯拉不打算长期继续其内部人工智能超级计算机的 Nvidia GPU 架构路径。这台 GPU 数量排名世界前 7 的机器仅仅是即将推出的Dojo超级计算机的前身,该超级计算机由 Elon Musk 在 2020 年首次宣布。一年前,我们看到了Tesla D1 Dojo 芯片,该芯片旨在取代Nvidia 的 GPU 可实现“每个粒度的最大性能、吞吐量和带宽”。
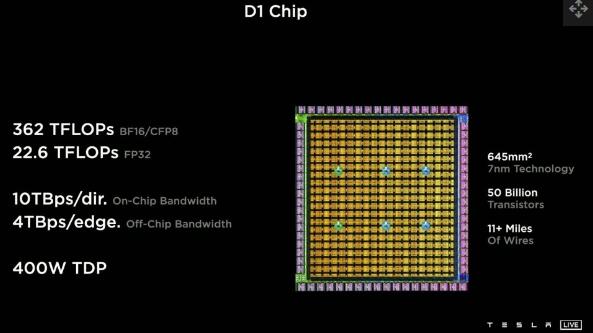
(图片来源:特斯拉)
Tesla Dojo D1 是一种定制的 ASIC(专用集成电路)芯片,用于 AI 训练,它是该领域的首批 ASIC 之一。目前的 D1 测试芯片是在台积电 N7 上制造的,包含大约 5000 万个晶体管。
有关 Dojo D1 芯片和 Dojo 系统的更多信息可能会在下周的 Hot Chips Symposium上公布——特斯拉计划在下周二举行三场演讲,讨论 Dojo D1 芯片架构、Dojo 和 ML 培训,以及通过系统集成实现人工智能。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。


































