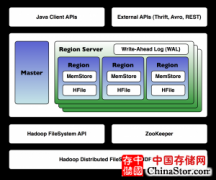
如何使用HBase的shell工具从命令行简单直接访问数据,了解HBase的深度技术架构,学习基础的Java API,并且了解如何避免用SQL的方式来设计HBase结构。
这是介绍Apache HBase系列文章的第一篇。本文提供HBase的概要介绍。在之后的文章中,你会看到如何使用HBase的shell工具从命令行简单直接访问数据,了解HBase的深度技术架构,学习基础的Java API,并且了解如何避免用SQL的方式来设计HBase结构。
导航:使用HBase处理海量数据系列文章共5章:1、HBase的概要介绍;2、初步了解HBase交互;3、HBASE架构了解;4、HBase中Java API使用;5、数据建模。
过去的几年中,在多种方式的数据存储和查询上,我们都看到了真正意义上的爆炸式发展。其中被称为NoSQL的数据库站在了改革的前沿(译注:原文leading the charge,我认为是打错了,应该是leading the change),正在形成新的持久化存储备选方案。NoSQL的流行很大程度应当归功于如Google、Amazon、Twitter和Facebook等大型公司,因为他们聚集了大量的数据需要进行保存、查询和分析。且越来越多的公司正在收集海量的数据,并且需要能够有效的全部利用来充实自己的业务。例如社交网络需要分析用户直接的社交关系并对关系用户进行推荐,同时几乎每个大型网站都有自己的推荐引擎向你推荐可能想要购买的商品。当数据积累越来越多,他们需要一个简单的方式来扩展整个系统而不是重新构建。
从19世纪70年代开始,关系型数据库 (RDBMS)几乎统治了数据管理场景。但是当业务不断扩大,存储和处理的数据量也不断增长,关系型数据库越来越难以扩展。一开始你可能从单机到主从节点,然后再数据库之上加入一道缓存层用于存储加载热点读写数据。当查询性能降低时,索引(indexes)常常是首先被丢弃的,接下来根据反范式( Denormalization )迅速避免关联(joins),因为该操作会很大程度消耗性能。之后你可能评估最耗性能的一些查询,修改使得这些查询能够变成有效的主键查询,或者将大表中的数据分布到多个数据库切片中(shards)。这个时候,你再回顾一下,会发现关系型数据库的很多关键优势已经被放弃了——引用完整性(referential integrity)、事务(ACID transactions)、索引(indexes)等等。当然,这里描述的场景是在你的业务非常成功的情况下,发展很快速需要处理越来越多的数据,持续以高比例增长的数据。换句话说,你就是下一个Twitter。
你是吗?也许你正研究一个环境监测项目,需要部署一个世界范围内的传感器网络,而所有的传感器会产生海量的数据。又或者你在研究DNA序列。假如你明白或者认为你要面对海量数据存储需求,有数十亿行及数百万列的情况,你应该考虑HBase。这类新数据库设计初衷就是在商业服务器集群中能够完成从基础建设到水平扩展阶段,而不需要垂直扩展设法去买更高级的机器(而且最终还是可能没法买到更好的机器)。
初入HBase
HBase是一个能够提供实时、随机读写,能够存储数十亿行和数百万列的数据库。它设计是要运行于一个商业服务器的集群之上,当新服务器添加之后能够自动扩展,还能保证同样的性能。另外,还要有很高的容错性,因为数据是分割至服务器集群中,保存在一个冗余的文件系统比如HDFS。当某些服务器异常时,你的数据仍然是安全的。这些数据会在当前活动的服务器中自动均衡直到替换服务器上线。HBase是高一致性的数据存储。你修改的内容能够马上在其他所有的客户前展示。
HBase是在谷歌的Bigtable之后建立的,谷歌在2006年发布了一份论文“稀疏的、分布式的、持久化多维排序图”。所以如果你习惯了关系型数据库,HBase初看来很陌生。还有表的概念,却不同于关系型数据库的表。不支持典型的关系型数据库概念如:关联(joins)、索引(indexes)、事务(ACID transactions)等。但你放弃了这些特性,却得到了扩展性和容错性。HBase实质是一个带有自动数据版本控制的键值(key-value)存储。
你能够按照你希望的那样进行增删改查的操作。也能够在HBase的表中按照顺序扫描数据行。当在HBase中进行数据扫描时,数据行总是按照行主键(row key)顺序返回。每行数据都由一个唯一排序后的行主键(可以认为是关系型数据库的主键)和任意数量的列,每列都属于一个列簇(column family)并且包含一个或多个版本的值。值都是简单的二进制数组,根据应用需要可以转换成需要展示或存储的形式。HBase并未试图对开发者隐藏面向列的数据模型,而且Java 的API显然比其他你可能使用的接口更加底层。比如JPA,甚至JDBC都比HBase的API更加抽象。HBase的操作基本在原生的层面。
总结
在这篇介绍性的文章当中,我们了解到HBase是非关系型、强一致性、自动数据版本控制的分布式键值数据库。能够通过向服务器集群中添加服务器来进行水平扩展,并且能够在服务器异常时提供保障数据完整的容错机制。我们还讨论了HBase表组织数据的方式,尤其是数据行包括一个唯一键、任意数量的列簇和一个列簇包含任意多的列。下篇文章中,我们将通过HBase的shell工具进行与HBase的第一步交互。
原文链接: dzone 翻译: ImportNew.com - 陈 晨 译文链接: http://www.importnew.com/8819.html
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。