介绍 Apache HBase 的基本知识,并展开介绍 IBM 对 HBase 的改进和扩展,HBase Master 多结点高可用支持,以及如何利用 IBM BigInsights 在 IBM Hadoop 集群中对 HBase 服务和作业提交进行监控和管理。
HBase 作为 BigTable 的一个开源实现,随着其应用的普及,越来越被各大企业应用于海量数据系统中。本文将向读者简要介绍 Apache HBase 的基本知识,并展开介绍 IBM 对 HBase 的改进和扩展,HBase Master 多结点高可用支持,以及如何利用 IBM BigInsights 在 IBM Hadoop 集群中对 HBase 服务和作业提交进行监控和管理。本文将帮助读者在大数据云计算 Hadoop 集群应用中利用 HBase 更加高效、直观、便捷地进行存储,查询和优化海量数据。
Apache HBase 的基本知识
2006 年 11 月,Google 发表了一篇名为《 BigTable 》论文 , 2007 年 2 月,Hadoop 的开发人员对其进行实现并命名为 HBase。 HBase 是基于 Hadoop 之上的一种新型的基于列存储的开源数据存储架构,用于解决大数据问题,是 Hadoop 的分布式数据库。
HBase 现在已经比较成熟,最新的稳定版本是 0.94.x。HBase 已经被很多大公司采用,如 Facebook, Twitter,Adobe, Cloudera, IBM, 等等。HBase 不是传统 RDBMS 意义上的基于列的数据库,而是利用磁盘进行列存储格式的数据库,其优势在于提供基于关键字的特定列和顺序范围的快速访问。
HBase 有三个重要的组件:客户端库,一个 master server(可以配置多个备用 master,后文将对此进行详细描述)以及多个 Region Server。Master 负责分配 Region 到各个不同的 Region Server 上,Region Server 负责存储实际的数据。同时,HBase 通过使用 ZooKeeper,一种可靠,高可用,一致性的分布式协同服务来帮助其完成相应的任务。HBase 集群管理员可以通过在系统运行过程中添加和删除 Region Server 节点来调节改变工作负载。HBase 以 HFile 作为存储数据的基本格式,其底层的文件系统默认采用 HDFS。
图 1. HBases 基本架构
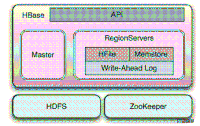
HBases 基本架构
图 1. 显示了不同的组件如 HDFS,Zookeeper 是怎样与 HBase 一起协调工作的。Master Server 负责处理跨 Region Server 的 regions 数据的导入平衡,卸载繁忙的 Region Server 负担,将 region 转移到更空余的 Region Server 上。
HBase Master 不负责实际的数据存储,它协调导入平衡,维护集群的状态,维护 schema 的更改和 metadata 元数据操作,如创建表和列族(column families),但从不提供任何数据服务。
Region servers 负责加载和维护 region,包括处理对其管理的 region 的所有读写请求,以及 region 大小增长到超过配置阀值的时候对其进行切分。
客户端通过与 Zookeeper 通信获取到其需要进行读写操作的 region 所在的 Region Server 之后,将直接与 Region Server 通信,并由 Region Server 处理所有相关的请求。
IBM BigInsights 架构中的 HBase
IBM Big Data(大数据)产品 InfoSphere BigInsights 是大数据管理与分析平台, 其底层架构也采用了 Hadoop 和 HBase 对结构化和非结构化数据进行存储和查询。
BigInsightsz 集群软件层次中的 HBase
BigInsights 整合了很多已有的 Hadoop 开源组件,如 HDFS, MapReduce, HBase, Zookeeper 等,将它们很好的融入 BigInsights 软件体系,并与其他 BigInsights 的组件一起协同工作在同一个平台上。 HBase 被用作 BigInsights 的存储数据库,Zookeeper 被用作 BigInsights 的服务协同组件。如果要使用 HBase, 我们需要同时安装 Hadoop, Zookeeper, 因为 HBase 采用 Hadoop 作为其文件系统,采用 Zookeeper 作为其服务协同支持。
当把 BigInsights 部署到一个集群上时,软件层次的结构如图 2. 所示:
图 2. BigInsights 中 Hadoop 开源组件列表

BigInsights 中 Hadoop 开源组件列表
HBase 安装和配置
BigInsights 产品集成了经过 IBM JDK 编译和一定改进扩展后的 HBase。在 BigInsights 产品的安装过程中可以通过安装界面选择和配置 HBase, 配置内容包括指定 HBase 安装路径,日志目录,指定集群中 HBase Master 和 HBase Regionservers 节点以及服务端口。HBase 的二进制软件包默认安装和配置在 BigInsights 集群的所有节点上,也就是说安装完 BigInsights 以后的每个 BigInsights 节点都可以作为 HBase 的客户端使用。
在安装 BigInsights 之前,需要从解压以后的根目录下运行 start.sh 脚本,然后在浏览器中输入 URL http://your-server:8300/Install/ 打开安装向导,安装向导将引领您完成后续的安装步骤,安装过程将包括:安装类型(选择多节点分布式集群安装和配置)选择,文件系统选择,组,用户名及 SSH 配置,指定集群节点,组件安装,安全类型选择等,下面给出具体的 HBase 以及 Zookeeper 的安装配置实例。
配置内容 配置信息
HBase master servers 指定 HBase Master 的节点名,可以是 IP,也可以是 hostname
HBase region servers 指定 HBase Regionserver 的节点名,可以是 IP,也可以是 hostname
Zookeeper mode 可选,有 shared/separate ZooKeeper 安装模式
HBase root directory 高级设置,默认为 /hbase( 可配置 )
HBase master port 60000( 可配置 )
HBase master UI port 60010( 可配置 )
HBase master server JMX port 10101( 可配置 )
HBase region server port 60020( 可配置 )
HBase region server UI port 60030( 可配置 )
HBase region server JMX port 10102( 可配置 )
图 3. HBase 安装和配置
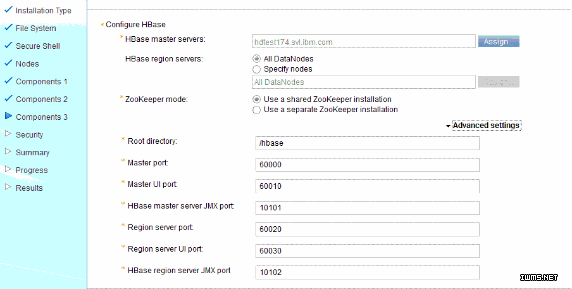
HBase 安装和配置
图 4. Zookeeper 安装和配置
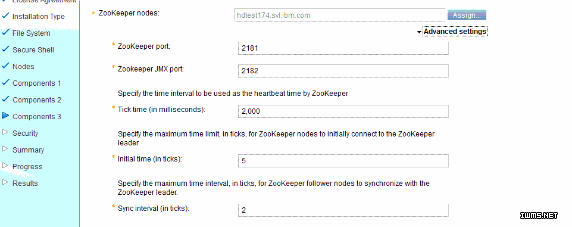
Zookeeper 安装和配置
最后,当安装完成以后,点击“Finish”或者在后台命令行运行“start.sh shutdown”关闭安装向导。
IBM 对 HBase 的改进和扩展
BigInsights 最大限度的提供了统一的,IBM 特有的 HBase 管理功能,包括用户界面以及后台命令行管理模式。这样,用户可以通过简单的界面操作或者后台命令来启停 / 查看 HBase 集群,而不用关心具体的实现细节。
与此同时,IBM 还提供了统一的用户界面和添加、删除节点命令来支持 HBase 集群的可伸缩性。
另外,HBase Master 多结点功能的实现,提供并保证了 HBase 在 BigInsights 中的高可用性。以下将对这些改进和扩展功能进行展开介绍。
IBM BigInsights 中的 HBase 集群管理和监控
BigInsights 集群为 HBase 提供了完备的管理功能,包括统一的 HBase 用户管理界面,后台命令行管理模式,HBase 服务状态监控,检查、同步、添加、删除、启动、停用、查看 HBase 服务,反向代理 UI,查看 HDFS 中的 HBase,HBase 应用程序提交等。
Web 界面管理 HBase 服务状态
通过 http:// 主节点主机名或 IP:8080/data/html/index.html 进入 BigInsights Web 管理控制台。使用 BigInsights 安装所有模块包括 Hadoop、Hbase、Zookeeper、Oozie、Flume 等。(注意:如果您使用的是 BigInsights Basic 版本,请使用 http:// 主节点主机名或 IP:8080/BigInsights 打开控制台。下文截图全部基于 Enterprise 版本,Basic 版本会略有差别。)
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。