上次去Hadoop大会,听了互联网的专场,对于阿里的云梯这个主题颇有些印象,但是由于对Hadoop纯属概念党,所以听的也不是太懂,今天在网上查了下这个云梯,其实网关于这个上面的还是挺多的,所以特别看了下:背景:阿里的云梯集群是承载了阿里巴巴过去五年来的
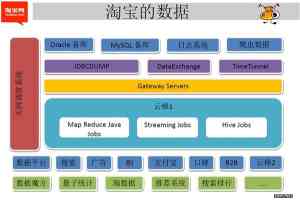
上次去Hadoop大会,听了互联网的专场,对于阿里的云梯这个主题颇有些印象,但是由于对Hadoop纯属概念党,所以听的也不是太懂,今天在网上查了下这个云梯,其实网关于这个上面的还是挺多的,所以特别看了下:
背景:阿里的云梯集群是承载了阿里巴巴过去五年来的集团及其子公司(淘宝、天猫、一淘、B2B等)业务的绝大部分业务数据基础平台,经历了近5年数据量的增长,服务器也不断的增长,从300到1000...直到现在的5000的倍数,好庞大的数据处理平台规模呀,表示很羡慕。关键是数据上升直接代表了他们的业务量和用户数是不断增长的。想想也是这么多服务器,机房规划估计早期也没想那么多,即便是Hadoop可以无限制的水平扩展,但是机房会有无限大的空间么,这就提出问题了,这个云梯集群机器太多了,数据量大了,业务查询肯定也慢了,Hadoop的优势就是分布式集群计算,所以就得继续扩充机器,那么还得规划一个新机房,进而想想做个Hadoop的跨机房的集群,那么问题就来了,从Hadoop的架构上来说:
Hadoop的namenode的节点本身只有一个,也就是单点的,无论你Datanode怎么扩展,但是这Namenode节点存储元数据信息,存储容量网络带宽,CPU内存等在一台主机上都是有极限的,那么扩了机房,你也得扩充namenode节点,当前不支持,如何让其支持,就得从技术层面解决。另外刚才提到机房间还有带宽问题,不过十有八九机房是不同一大楼,所以就得有个城域网概念了,直接拉光纤吧,呵呵,这个是我自己个人觉得,也不知道人家怎么解决的。
难点3.跨两个机房的Hadoop集群数据怎么分布呢,如果说上面单namenode问题解决了,下面网络带宽问题解决了,接下来这个也很关键,应该得考虑从应用层面切割,应该是纵向切割吧,一个机房内的主机数据通信总比跨机房快吧,但是毕竟一个集群呀,分布式运算嘛,计算调度怎么跨机房呢,这个也是个问题。
好吧,上面的问题都解决了,那么以后如何升级维护呀,是软件总有这样那样的BUG,再说Hadoop软件在不停的更新,好多新功能在新的开源版本上,这么大个集群升级管理起来真的是个大问题呀,只能说牛逼的不得了,这些问题都想通了,那么这些真的可以实现吗,理论上可行但是实际不一定可行哦,所以实践是检验真理的唯一标准。
看完这一切真的很佩服得阿里人的勇气和敢于行动的这帮技术人,尤其是上层给了他们IT部门的支持力度也够大的,都说电商企业其实是一个技术公司,这点看来确实是,阿里巴巴的技术人应该非常自豪,他们在技术架构业务应用实际已经走到了前列,当现在大部分公司都炒作Hadoop大数据时,其实他们已经玩的很熟练了,真是祖国的骄傲呀。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。










