在大数据技术中,Apache Hadoop和MapReduce是最受用户关注的。但管理Hadoop分布式文件系统,或用Java编写执行MapReduce任务则不是简单的事。那么Apache Hive也许能帮助您解决这一难题。Hive数据仓库工具也是Ap
在大数据技术中,Apache Hadoop和MapReduce是最受用户关注的。但管理Hadoop分布式文件系统,或用Java编写执行MapReduce任务则不是简单的事。那么Apache Hive也许能帮助您解决这一难题。

Hive数据仓库工具也是Apache Foundation的一个项目,同时是Hadoop生态系统的关键组件之一,它提供了基于语境的查询语句,即Hive查询语句。这套语句可以将SQL类查询自动翻译成MapReduce工作指令。
在BI领域,包括IBM DB2、Oracle和SQL Server在内的关系型数据库一直处于统治地位。这使得SQL成为商业智能的首选语言,大部分数据分析专家都掌握了较强较全面的SQL技能。同样道理,做数据分析的专家对Excel,Pivot表格和图表等工具更熟悉。
先让我们来看一个端到端的BI项目在Windows Azure系统中是如何运行的。在Excel图表中显示美国航空公司的航班正点到达的数据,数据量很大,整个过程不需要编写任何程序代码。
Windows Azure CTP上的Apache Hadoop
去年年底,微软SQL Server研发团队宣布了Windows Azure平台上的Apache Hadoop功能,即HadoopOnAzure。微软方面称这将简化Hadoop的使用和设置,利用Hive来从Hadoop集群中提取非结构化的数据,并在Excel工具中进行分析,同时增强了Windows Azure的弹性。
HadoopOnAzure的社区预览版还处于未公开状态,用户需要在Microsoft Connect上填写一个简单的问卷调查来获得邀请码,并通过Windows Live ID登陆。输入唯一的DNS用户名,选择初始Hadoop集群大小,提供一个集群登录名和密码,点击Request Cluster按钮。(见图1)
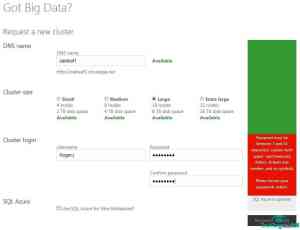
图1 用户只需简单的操作即可修改一个集群设置(点击放大)
开通并设置集群需要15到30分钟时间。HadoopOnAzure社区预览版的资源是免费的,但开通集群24小时之内,你需要在最后6小时的时候更新一下订阅。此后的使用过程中,证书需要每天都更新一次。
用户如要使用Windows Azure的blob持久性数据存储,那么就需要一个Windows Azure的订阅和一个存储账户。否则当集群超时,所有存储在HDFS上的数据都将丢失。如果没有订阅,用户还可以申请注册免费试用三个月的 Windows Azure账号,这个账号赠送每位用户20GB存储空间、上百万次存储传输以及20GB的外网带宽。
向SQL Azure blob中填充大数据
这个Apache Hive项目从美国联邦航空管理局(FAA)提取数据,收集了2011年后5个月到2012年1月共6个月以来航班正点到达的信息及延误信息。6页文本资料子集包涵FAA文件栏,栏下有50万行数据每页25 MB。
用户需要将数据上传到一个blob container的文件夹中,这样Hive可搜索到这些数据。关于如何创建Azure blob源数据的详细步骤,可以参考我之前的一篇文章。文章还提到了数据文件以及如何用Windows Live SkyDrive账号下载数据,最后怎样将数据上传到Windows Azure blob的具体步骤。
集群配置完成后,将弹出Elastic MapReduce门户登录页面和集群、账户管理对话框。(见图2)
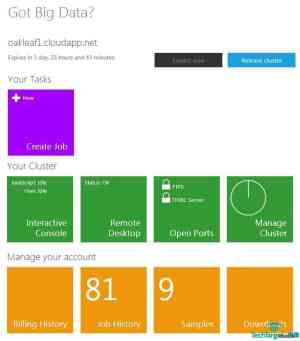
图2:HadoopOnAzure的MapReduce控制板页面特性和功能。(点击放大)
复制Windows Azure管理门户的Primary Access Key保存到剪切板,点击Manage Cluster,打开页面然后点击Set Up ASV(Azure存储库),将Windows存储账户作为Hive表的数据源。此外,用户还可以使用Amazon S3或Windows Azure Dataplace DataMarket中的数据作为Hive表的数据源。
输入你的存储账号,在Passkey框中粘贴Primary Access Key,点击保Save Settings,Hive即可成功登录数据库访问blob。如果证书获得认证,用户将收到短信通知Azure账号设置成功。
与HDFS不同,即便是最简单的KV(Key-Value)数据,Hive表都需要有schema。要从非HDFS或外部制表符号数据中生成一个 Hive表,给其列命名并定义数据类型的话,用户就需要运行 CREATE EXTERNAL TABLE语句,如下面的HiveQL所示:
CREATE EXTERNAL TABLE flightdata_asv (
year INT,
month INT,
day INT,
carrier STRING,
origin STRING,
dest STRING,
depdelay INT,
arrdelay INT
)
COMMENT 'FAA on-time data'
ROW FORMAT DELIMITED FIELDS TERMINATED by '9'
STORED AS TEXTFILE
LOCATION 'asv://aircarrier/flightdata';
Apache Hive的数据类型相对较少,并且不支持日期或时间字段,好在源数据*.csv对应的整数字段如年,月和日数值正好有利于数据的维护。出发(depdelay)和到达(arrdelay)的延误时间值将以分钟的形式呈现。
执行动态HiveQL语句,可以点击Elastic MapReduce的Interactive Console,然后点击Hive按钮打开动态Hive页面,页面顶部出现只读文本框,点击下方文本框为说明。(见图3)
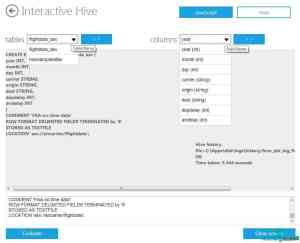
图3:Hive图表选项列表包括新图表标题,列单元格显示某个选定图表字段名。点击﹥﹥键在单元格中插入选定的条目。(点击放大)
下载并安装Apache Hive ODBC驱动及Excel插件
返回Elastic MapReduce主页面,点击Downloads面板。找到与用户Excel版本对应的安装链接,然后点击Run,打开警告对话框。点击More Options,出现Run Anyway选项,点击开始安装,打开ODBC驱动启动Hive设置对话。在I Accept框中打钩。
点击Install开始安装驱动,完成后点击Finish退出安装。下一步,打开Excel,点击Data标签,确认Hive Pane图标存在,点击图标,工作表右面出现Hive Query仪表盘。安装插件会放置一个Hive Pane图标到目录的Hive Data部分。
返回EMR控制主页面,点击Open Ports打开Configure Ports页面,点击ODBC Server,往右拖动,打开TCP port 10000。
执行交互式Apache Hive查询
返回Excel,点击Hive Pane图标,打开Hive Query任务框,点击Enter Cluster Details来打开ODBC Hive Setup对话框,输入一个描述及DNS主机名称,接受TCP端口。下一步,选择Username/Password authentication,输入你的Elastic MapReduce门户实例的用户名及密码。(见图4)
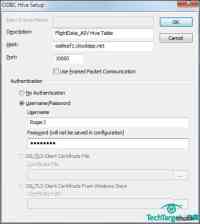
图4:每个链接,机场,TCP端口和集群用户名密码都有其对应的具体名称。(点击放大)
若ODBC Hive对话框中设置的Hive选项正确,那么当用户打开Select or Enter Hive Connection时,输入的名称会作为描述字段弹出。打开Select the Hive Object to Query列表,选择flightdata_asv生成Columns列表。
如要执行一个聚合查询来显示延误的平均时间,可以勾选carrier和arrdelay栏,打开arrdelay字段的函数列表,然后双击列表中的avg,将其添加到HiveQL语句当中(见图5)。
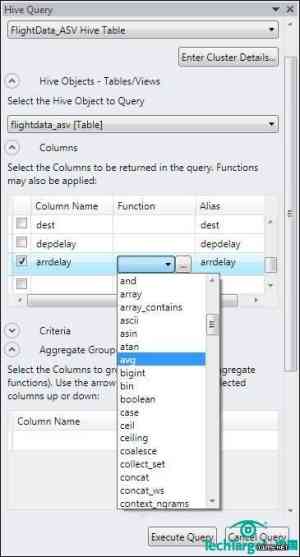
图5:选择avg HiveQL进行聚合查询并双击,HiveQL功能比大多数的SQL更丰富一些
下一步,划去Limit Results勾选框,打开Aggregate Grouping列表,选择carrier列。
在avg()中输入arrdelay,如avg(arrdelay),这可以消除查询语句设计流程的缺陷,点击Execute Query得出查询结果。(见图6)
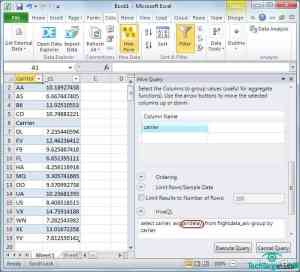
图6:这是HiveQL查询执行后的结果,B6好F9是FAA专用的两个字节代码,B6指代Jet Blue,F9指代Frontier Airlines。
删除错误的Carrier条目,这可能是由于每列的首标发生错误,导致信息被留在了文档中,结果出现在查询结果里。保留一位小数,关掉任务框,将信息添加到工作表,添加标题,X轴标题和数据标签。(见图7)
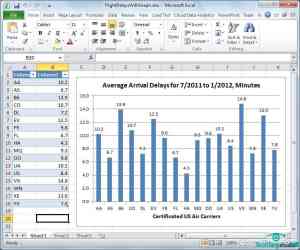
图7:Excel表单从图6的数据中生成得来
文章给出的例子阐述了运行HadoopOnAzure CTP的简单流程。微软代码为“Cloud Numerics” 的项目也有相似的功能,但是它需要我们在Visual Studio 10以上版本的环境中进行操作。HadoopOnAzure能够将表格数据直接传送到Excel当中,以便做进一步的分析。此外,交互式Hive、 Hive ODBC数据源以及对应的Excel插件,都使得HadoopOnAzure成为大数据处理的理想平台。
原文链接:http://www.searchbi.com.cn/showcontent_62711.htm
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。









