codec其实就是coder和decoder两个单词的词头组成的缩略词。使用CompressionCodes解压缩 CompressionCodec有两个方法可以方便的压缩和解压。 压缩:通过createOutputStream(OutputStream out)方法获得CompressionOutputStream对象
codec其实就是coder和decoder两个单词的词头组成的缩略词。CompressionCodec定义了压缩和解压接口,我们这里讲的codec就是实现了CompressionCodec接口的一些压缩格式的类,下面是这些类的列表: 
使用CompressionCodes解压缩 CompressionCodec有两个方法可以方便的压缩和解压。 压缩:通过createOutputStream(OutputStream out)方法获得CompressionOutputStream对象 解压:通过createInputStream(InputStream in)方法获得CompressionInputStream对象 压缩的示例代码 [java] view plaincopy
- package com.sweetop.styhadoop;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.io.IOUtils;
- import org.apache.hadoop.io.compress.CompressionCodec;
- import org.apache.hadoop.io.compress.CompressionOutputStream;
- import org.apache.hadoop.util.ReflectionUtils;
- /**
- * Created with IntelliJ IDEA.
- * User: lastsweetop
- * Date: 13-6-25
- * Time: 下午10:09
- * To change this template use File | Settings | File Templates.
- */
- public class StreamCompressor {
- public static void main(String[] args) throws Exception {
- String codecClassName = args[0];
- Class<?> codecClass = Class.forName(codecClassName);
- Configuration conf = new Configuration();
- CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(codecClass, conf);
- CompressionOutputStream out = codec.createOutputStream(System.out);
- IOUtils.copyBytes(System.in, out, 4096, false);
- out.finish();
- }
- } 从命令行接受一个CompressionCodec实现类的参数,然后通过ReflectionUtils把实例化这个类,调用CompressionCodec的接口方法对标准输出流进行封装,封装成一个压缩流,通过IOUtils类的copyBytes方法把标准输入流拷贝到压缩流中,最后调用CompressionCodec的finish方法,完成压缩。 再来看下命令行: [plain] view plaincopy
- echo "Hello lastsweetop" | ~/hadoop/bin/hadoop com.sweetop.styhadoop.StreamCompressor org.apache.hadoop.io.compress.GzipCodec | gunzip - 使用GzipCodec类来压缩“Hello lastsweetop”,然后再通过gunzip工具解压。 我们来看一下输出: [plain] view plaincopy
- [exec] 13/06/26 20:01:53 INFO util.NativeCodeLoader: Loaded the native-hadoop library
- [exec] 13/06/26 20:01:53 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
- [exec] Hello lastsweetop
使用CompressionCodecFactory解压缩 如果你想读取一个被压缩的文件的话,首先你得先通过扩展名判断该用哪种codec,可以看下 hadoop深入研究:(七)——压缩 中得对应关系。 当然有更简便得办法,CompressionCodecFactory已经帮你把这件事做了,通过传入一个Path调用它得getCodec方法,即可获得相应得codec。我们来看下代码 [java] view plaincopy
- package com.sweetop.styhadoop;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IOUtils;
- import org.apache.hadoop.io.compress.CompressionCodec;
- import org.apache.hadoop.io.compress.CompressionCodecFactory;
- import java.io.IOException;
- import java.io.InputStream;
- import java.io.OutputStream;
- import java.net.URI;
- /**
- * Created with IntelliJ IDEA.
- * User: lastsweetop
- * Date: 13-6-26
- * Time: 下午10:03
- * To change this template use File | Settings | File Templates.
- */
- public class FileDecompressor {
- public static void main(String[] args) throws Exception {
- String uri = args[0];
- Configuration conf = new Configuration();
- FileSystem fs = FileSystem.get(URI.create(uri), conf);
- Path inputPath = new Path(uri);
- CompressionCodecFactory factory = new CompressionCodecFactory(conf);
- CompressionCodec codec = factory.getCodec(inputPath);
- if (codec == null) {
- System.out.println("No codec found for " + uri);
- System.exit(1);
- }
- String outputUri = CompressionCodecFactory.removeSuffix(uri, codec.getDefaultExtension());
- InputStream in = null;
- OutputStream out = null;
- try {
- in = codec.createInputStream(fs.open(inputPath));
- out = fs.create(new Path(outputUri));
- IOUtils.copyBytes(in,out,conf);
- } finally {
- IOUtils.closeStream(in);
- IOUtils.closeStream(out);
- }
- }
- }
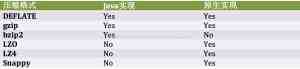
注意看下removeSuffix方法,这是一个静态方法,它可以将文件的后缀去掉,然后我们将这个路径做为解压的输出路径。CompressionCodecFactory能找到的codec也是有限的,默认只有三种org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.DefaultCodec,如果想添加其他的codec你需要更改io.compression.codecs属性,并注册codec。原生库 现在越来越多原生库的概念,hdfs的codec也不例外,原生库可以极大的提升性能比如gzip的原生库解压提高50%,压缩提高10%,但不是所有codec都有原生库的,而一些codec只有原生库。我们来看下列表:
 linux下,hadoop以前提前编译好了32位的原生库和64位的原生库,我们看下: [plain] view plaincopy
linux下,hadoop以前提前编译好了32位的原生库和64位的原生库,我们看下: [plain] view plaincopy - [hadoop@namenode native]$pwd
- /home/hadoop/hadoop/lib/native
- [hadoop@namenode native]$ls -ls
- total 8
- 4 drwxrwxrwx 2 root root 4096 Nov 14 2012 Linux-amd64-64
- 4 drwxrwxrwx 2 root root 4096 Nov 14 2012 Linux-i386-32 如果是其他平台的话,你就需要自己编译了,详细步骤请看这里http://wiki.apache.org/hadoop/NativeHadoop java原生库的路径可以通过java.library.path指定,在bin目录下,hadoop的启动脚本已经指定,如果你不用这个脚本,那么你就需要在你的程序中指定了,hadoop脚本中指定原生库路径的片段: [plain] view plaincopy
- if [ -d "${HADOOP_HOME}/build/native" -o -d "${HADOOP_HOME}/lib/native" -o -e "${HADOOP_PREFIX}/lib/libhadoop.a" ]; then
- if [ -d "$HADOOP_HOME/build/native" ]; then
- JAVA_LIBRARY_PATH=${HADOOP_HOME}/build/native/${JAVA_PLATFORM}/lib
- fi
- if [ -d "${HADOOP_HOME}/lib/native" ]; then
- if [ "x$JAVA_LIBRARY_PATH" != "x" ]; then
- JAVA_LIBRARY_PATH=${JAVA_LIBRARY_PATH}:${HADOOP_HOME}/lib/native/${JAVA_PLATFORM}
- else
- JAVA_LIBRARY_PATH=${HADOOP_HOME}/lib/native/${JAVA_PLATFORM}
- fi
- fi
- if [ -e "${HADOOP_PREFIX}/lib/libhadoop.a" ]; then
- JAVA_LIBRARY_PATH=${HADOOP_PREFIX}/lib
- fi
- fi hadoop会去查找对应的原生库,并且自动加载,你不需要关心这些设置。但某些时候你不想使用原生库,比如调试一些bug的时候,那么可以通过hadoop.native.lib设置为false来实现。 如果你用原生库做大量的压缩和解压的话可以考虑用CodecPool,有点象连接迟,这样你就无需频繁的去创建codec对象。 [java] view plaincopy
- package com.sweetop.styhadoop;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.io.IOUtils;
- import org.apache.hadoop.io.compress.CodecPool;
- import org.apache.hadoop.io.compress.CompressionCodec;
- import org.apache.hadoop.io.compress.CompressionOutputStream;
- import org.apache.hadoop.io.compress.Compressor;
- import org.apache.hadoop.util.ReflectionUtils;
- /**
- * Created with IntelliJ IDEA.
- * User: lastsweetop
- * Date: 13-6-27
- * Time: 上午11:53
- * To change this template use File | Settings | File Templates.
- */
- public class PooledStreamCompressor {
- public static void main(String[] args) throws Exception {
- String codecClassName = args[0];
- Class<?> codecClass = Class.forName(codecClassName);
- Configuration conf = new Configuration();
- CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(codecClass, conf);
- Compressor compressor = null;
- try {
- compressor = CodecPool.getCompressor(codec);
- CompressionOutputStream out = codec.createOutputStream(System.out, compressor);
- IOUtils.copyBytes(System.in, out, 4096, false);
- out.finish();
- } finally {
- CodecPool.returnCompressor(compressor);
- }
- }
- } 代码比较容易理解,通过CodecPool的getCompressor方法获得Compressor对象,该方法需要传入一个codec,然后Compressor对象在createOutputStream中使用,使用完毕后再通过returnCompressor放回去。 输出结果如下: [plain] view plaincopy
- [exec] 13/06/27 12:00:06 INFO util.NativeCodeLoader: Loaded the native-hadoop library
- [exec] 13/06/27 12:00:06 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
- [exec] 13/06/27 12:00:06 INFO compress.CodecPool: Got brand-new compressor
- [exec] Hello lastsweetop
- echo "Hello lastsweetop" | ~/hadoop/bin/hadoop com.sweetop.styhadoop.StreamCompressor org.apache.hadoop.io.compress.GzipCodec | gunzip - 使用GzipCodec类来压缩“Hello lastsweetop”,然后再通过gunzip工具解压。 我们来看一下输出: [plain] view plaincopy
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。