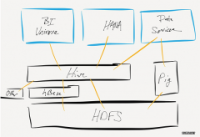
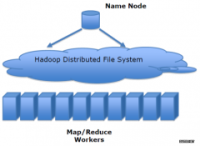
Hadoop NameNode 在内存中保存所有文件的“元信息”数据。据统计,每一个文件需要消耗 NameNode600 字节内存。如果需要保存大量的小文件会对NameNode 造成极大的压力。
使用 使用使用 使用 HDFS 保存大量小文件的缺点:
1.Hadoop NameNode 在内存中保存所有文件的“元信息”数据。据统计,每一个文件需要消耗 NameNode600 字节内存。如果需要保存大量的小文件会对NameNode 造成极大的压力。
2.如果采用 Hadoop MapReduce 进行小文件的处理,那么 Mapper 的个数就会跟小文件的个数成线性相关(备注:FileInputFormat 默认只对大于 HDFS Block Size的文件进行划分)。如果小文件特别多,MapReduce 就会在消耗大量的时间进行Map 进程的创建和销毁。
为了解决大量小文件带来的问题,我们可以将很多小文件打包,组装成一个大文件。 Apache Avro 是语言独立的数据序列化系统。 Avro 在概念上分为两部分:模式(Schema)和数据(一般为二进制数据)。Schema 一般采用 Json 格式进行描述。Avro 同时定义了一些自己的数据类型如表所示:
Avro基础数据类型
|
类型 |
描述 |
模式 |
|
null |
The absence of a value |
"null" |
|
boolean |
A binary value |
"boolean" |
|
int |
32位带符号整数 |
"int" |
|
long |
64位带符号整数 |
"long" |
|
float |
32位单精度浮点数 |
"float" |
|
double |
64位双精度浮点数 |
"double" |
|
bytes |
byte数组 |
"bytes" |
|
string |
Unicode字符串 |
"string" |
|
类型 |
描述 |
模式 |
|
array |
An ordered collection of objects. All objects in a particular array must have the same schema. |
{ "type": "array", "items": "long" } |
|
map |
An unordered collection of key-value pairs. Keys must be strings and values may be any type, although within a particular map, all values must have the same schema. |
{ "type": "map", "values": "string" } |
|
record |
A collection of named fields of any type. |
{ "type": "record", "name": "WeatherRecord", "doc": "A weather reading.", "fields": [ {"name": "year", "type": "int"}, {"name": "temperature", "type": "int"}, {"name": "stationId", "type": "string"} ] } |
|
enum |
A set of named values. |
{ "type": "enum", "name": "Cutlery", "doc": "An eating utensil.", "symbols": ["KNIFE", "FORK", "SPOON"] } |
|
fixed |
A fixed number of 8-bit unsigned bytes. |
{ "type": "fixed", "name": "Md5Hash", "size": 16 } |
|
union |
A union of schemas. A union is represented by a JSON array, where each element in the array is a schema. Data represented by a union must match one of the schemas in the union. |
[ "null", "string", {"type": "map", "values": "string"} ] |
Avro复杂数据类型

通过上图所示,通过程序可以将本地的小文件进行打包,组装成一个大文件在HDFS中进行保存,本地的小文件成为Avro的记录。具体的程序如下面的代码所示:
public class Demo {
public static final String FIELD_CONTENTS = "contents";
public static final String FIELD_FILENAME = "filename";
public static final String SCHEMA_JSON = "{"type": "record","name": "SmallFilesTest", "
+ ""fields": ["
+ "{"name":""
+ FIELD_FILENAME
+ "","type":"string"},"
+ "{"name":""
+ FIELD_CONTENTS
+ "", "type":"bytes"}]}";
public static final Schema SCHEMA = new Schema.Parser().parse(SCHEMA_JSON);
public static void writeToAvro(File srcPath, OutputStream outputStream) throws IOException {
DataFileWriter<Object> writer = new DataFileWriter<Object>(new GenericDatumWriter<Object>()).setSyncInterval(100);
writer.setCodec(CodecFactory.snappyCodec());
writer.create(SCHEMA, outputStream);
for (Object obj : FileUtils.listFiles(srcPath, null, false)){
File file = (File) obj;
String filename = file.getAbsolutePath();
byte content[] = FileUtils.readFileToByteArray(file);
GenericRecord record = new GenericData.Record(SCHEMA);
record.put(FIELD_FILENAME, filename);
record.put(FIELD_CONTENTS, ByteBuffer.wrap(content));
writer.append(record);
System.out.println(file.getAbsolutePath() + ":"+ DigestUtils.md5Hex(content));
}
IOUtils.cleanup(null, writer);
IOUtils.cleanup(null, outputStream);
}
public static void main(String args[]) throws Exception {
Configuration config = new Configuration();
FileSystem hdfs = FileSystem.get(config);
File sourceDir = new File(args[0]);
Path destFile = new Path(args[1]);
OutputStream os = hdfs.create(destFile);
writeToAvro(sourceDir, os);
}
}
public class Demo {
private static final String FIELD_FILENAME = "filename";
private static final String FIELD_CONTENTS = "contents";
public static void readFromAvro(InputStream is) throws IOException {
DataFileStream<Object> reader = new DataFileStream<Object>(is,new GenericDatumReader<Object>());
for (Object o : reader) {
GenericRecord r = (GenericRecord) o;
System.out.println(r.get(FIELD_FILENAME)+ ":"+DigestUtils.md5Hex(((ByteBuffer)r.get(FIELD_CONTENTS)).array()));
}
IOUtils.cleanup(null, is);
IOUtils.cleanup(null, reader);
}
public static void main(String... args) throws Exception {
Configuration config = new Configuration();
FileSystem hdfs = FileSystem.get(config);
Path destFile = new Path(args[0]);
InputStream is = hdfs.open(destFile);
readFromAvro(is);
}
}
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。