大数据新手入门hadoop的初步理解:hadoop的初步理解 1:hadoop到底是什么呢? hadoop是一个解决方案,是一个能够处理大数据量的的分布式处理系统。
大数据新手入门hadoop的初步理解
1:hadoop到底是什么呢,
他是一个解决方案,是一个能够处理大数据量的的分布式处理的解决方案,他是google的模仿衍生产品。
它是利用了google发表的Mapreduce论文编写变成模型和框架。 ?他主要是把大的任务分割小的任务,并把这些小的任务交给集群上的单点执行。
什么叫做Job呢,在MapReduce中,一个准备提交执行的应用程序叫做:job(作业,就像一个工程一样),而Job呢,太大了,就会分割成成N份,执行于计算机各个节点上,而这种单元叫做 task(任务)。
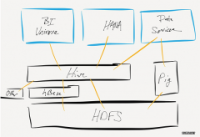
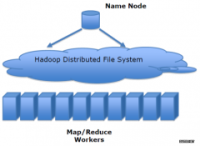
Hadoop 提供的分布式文件系统(HDFS)主要是来处理各个节点上的存储,并实现了高吞吐率的数据编写。
简单的说,就是一个资源的存储,和一个资源的查找。
hadoop在分布式存储和分布式计算方面,Hadoop都是用了主/从(Master/slave)架构。这里面有一系列的后台(deamon)程序。不同的后台程序扮演者不同的角色,这些角色: NameNode secondaryNameNode,JobTracker,TaskTracker,DataNode,这些名字呢,只要碰过hadoop都会见到,在master节点上呢,主要有的是NameNode,secondaryNameNode,JobTracker,在slave节点上主要是由DataNode,tasktracker。
? ? ? ? ?Master节点,得看系统的大小,而进行不同的部署。当Master大的时候呢,可以对Master中的NameNode 和secondaryNameNode节点,和JobTracker分配部署在两台服务器上。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。