这是来自于阿里技术嘉年华的一个分享,因为在百度也考虑过类似的事情,所以听得比较有感悟,这里把相关内容整理一下。首先尊重版权,还是把原链接和作者贴上:http://adc.alibabatech.org/carnival/history/schedule
这是来自于阿里技术嘉年华的一个分享,因为在百度也考虑过类似的事情,所以听得比较有感悟,这里把相关内容整理一下。
首先尊重版权,还是把原链接和作者贴上:
http://adc.alibabatech.org/carnival/history/schedule/2013/detail/main/286?video=0
来自于阿里吴威工程师的分享
首先需要说明一点,跨机房hadoop可能应用场景并不是很多,国内像BAT这种巨头也许需要,但是大部分的中小公司也许并不需要这个,也许这是个屠龙之技,呵呵。
把这个问题分三段来讲,第一段是问题出现的背景,第二段是解决该问题的难点,第三段是最终的解决方案。
(一) 背景:
先要看下为什么需要做一个跨机房的大集群?
大集群的优点在于数据管理和授权容易(这个问题在一个多部门的大公司还是很重要的);跨部门的使用数据容易,无需重复拉取数据。
在集群达到一定规模时,单机房(机房内的容量是有限的)已经无法满足集群的需求了,要想一劳永逸的解决问题,需要建设一个跨机房的hadoop集群。
(二)技术挑战:
2.1 NameNode的性能问题:
在管理一个巨大的hadoop集群时,由于原始的Namenode是单节点,因此会成为一个性能瓶颈,遇到的性能问题主要包括两方面:存储容量问题(存储元数据)和计算压力(处理rpc请求,修改内存树时候需要全局锁)问题。
其中存储容量问题可以依赖内存的垂直扩展来解决,但是计算压力却很难通过提升硬件来解决(因为目前厂商的主要发展方向是多核,而非提高主频)
2.2机房之间的网络限制:
机房之间的网络永远是个硬件条件的限制,跨机房的网络传输带来了数据延时和带宽限制:
1, 延时一般是在10ms之内,而hadoop上大部分运行的是离线作业,基本可接受
2, 带宽限制的问题比较大,因为单机房内的点对点带宽一般是在1Gbps,而机房之间的带宽确在20Mbps左右,非常有限。
2.3资源组之间的管理
每个部门可以看做一个资源组,它们可能会互相使用对方的数据,因此如何规划计算和存储的位置就很重要,否则会在多个机房之间出现大量的数据拷贝。
(三)解决方案:
先看下整个跨集群hadoop的架构图:
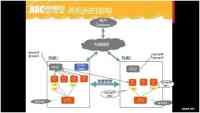
重点介绍里面三点,也就是和上面三个问题相对应的:
1, 可以看到这里画出了两个NN(namenode),它们实际上还是属于一个hadoop集群,这是业界里的一个解决方案:HDFS Fedaration,它为了解决元数据节点性能问题;
2, 可以看到这里有一个cross node节点,它是用来在两个机房之间同步数据的,它的设计考虑到了机房间的网络限制;
3, 最后是groupA、groupB,这是为了解决数据产出方和使用方关系来用的。
3.1 Federation
Federation相关资料见:
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/Federation.html#HDFS_Federation
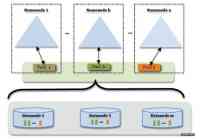
为了水平扩展Namenode,federation使用了多个互相独立的namenode。它们之间互相不需要通信,每个datenode需要向全部namenode注册并发送信息。
BlockPool是属于一个namenode的block集合,每个blockpool之间也是互相独立的。
在federation里,有一个需要关注的问题,就是多个namenode的地址如何对用户进行透明?它采用的解决方案是目录树挂载的方案(社区有个viewFS,应该就是为了解决这个问题):熟悉linux或者nfs的朋友应该都知道mount这个概念,目录树挂载就是这个意思。
不过使用目录树挂载也存在着一个问题,就是各个子目录下的存储资源需要人为的介入管理,不能出现严重的不均。
3.2 crossNode
机房间的网络限制要求不能出现大规模、长时间的数据拷贝,需要一个专门管理机房间数据拷贝的进程,叫做crossNode。它是独立部署的一个节点,和元数据节点是分离的。
它能提供的功能概括来说主要包括以下三点:
a) 根据预置的跨机房文件,进行数据拷贝
b) 处理实时的数据拷贝请求
c) 进行跨机房的数据流量控制
如何得知跨机房文件列表?
由于离线任务基本都是定时触发的,可以根据对历史作业的分析来形成一个跨机房文件列表
3.3 资源组之间的管理
各个资源组之间存在数据的依赖,我们希望通过资源组管理,能实现大部分任务在本机房内产出数据,只有少量跨机房产出数据;大部分任务读取本机房的数据副本,只有少量跨机房读取数据。
为了标识资源组之间的数据依赖性,定义一个资源组之间的距离概念:一个资源组访问另一个资源组的数据量越多,则两者的距离越近,应该将距离接近的资源组放在同一个机房内。
为了让计算和产出尽可能地靠近,使用一个MRProxy,对于不同类型的任务做不同处理:
a) 离线计算:跨机房列表中的数据正在传输中(DC1->DC2),DC2上的 Job 被暂停调度,等待传输完毕
b) Ad-hoc查询:DC2上的 Job 需要读DC1上的数据,Job暂停调度,通知 CrossNode,数据传输完毕后继续调度
c) 特殊情况:跨机房数据 Join,DC1大表,DC2小表,Job 调度到DC1上,跨机房直接读取DC2数据,无需等待
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。










