Hadoop Streaming是Hadoop提供的多语言编程工具,用户可以使用自己擅长的编程语言(比如python、php或C#等)编写Mapper和Reducer处理文本数据。Hadoop Streaming自带了一些配置参数可友好地支持多字段文本数据的处
Hadoop Streaming是Hadoop提供的多语言编程工具,用户可以使用自己擅长的编程语言(比如python、php或C#等)编写Mapper和Reducer处理文本数据。Hadoop Streaming自带了一些配置参数可友好地支持多字段文本数据的处理,参与Hadoop Streaming介绍和编程,可参考我的这篇文章:“Hadoop Streaming编程实例”。然而,随着Hadoop应用越来越广泛,用户希望Hadoop Streaming不局限在处理文本数据上,而是具备更加强大的功能,包括能够处理二进制数据;能够支持多语言编写Combiner等组件。随着Hadoop 2.x的发布,这些功能已经基本上得到了完整的实现,本文将介绍如何使用Hadoop Streaming处理二进制格式的文件,包括SequenceFile,HFile等。
注:本文用到的程序实例可在百度云:hadoop-streaming-binary-examples 下载。
在详细介绍操作步骤之前,先介绍本文给出的实例。假设有这样的SequenceFile,它保存了手机通讯录信息,其中,key是好友名,value是描述该好友的一个结构体或者对象,为此,本文使用了google开源的protocol buffer这一序列化/反序列化框架,protocol buffer结构体定义如下:
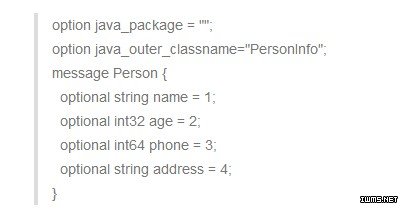
SequenceFile文件中的value便是保存的Person对象序列化后的字符串,这是典型的二进制数据,不能像文本数据那样可通过换行符解析出每条记录,因为二进制数据的每条记录中可能包含任意字符,包括换行符。
一旦有了这样的SequenceFile之后,我们将使用Hadoop Streaming编写这样的MapReduce程序:这个MapReduce程序只有Map Task,任务是解析出文件中的每条好友记录,并以name t age,phone,address的文本格式保存到HDFS上。
1. 准备数据
首先,我们需要准备上面介绍的SequenceFile数据,生成数据的核心代码如下:


需要注意的,Value保存类型为BytesWritable,使用这个类型非常容易犯错误。当你把一堆byte[]数据保存到BytesWritable后,通过BytesWritable.getBytes()再读到的数据并不一定是原数据,可能变长了很多,这是因为BytesWritable采用了自动内存增长算法,你保存的数据长度为size时,它可能将数据保存到了长度为capacity(capacity>size)的buffer中,这时候,你通过BytesWritable.getBytes()得到的数据最后一些字符是多余的,如果里面保存的是protocol buffer序列化后的字符串,则无法反序列化,这时候可以使用BytesWritable.setCapacity (value.getSize())将后面多余空间剔除掉。
2. 使用Hadoop Streaming编写C++程序
为了说明Hadoop Streaming如何处理二进制格式数据,本文仅仅以C++语言为例进行说明,其他语言的设计方法类似。
先简单说一下原理。当输入数据是二进制格式时,Hadoop Streaming会对输入key和value进行编码后,通过标准输入传递给你的Hadoop Streaming程序,目前提供了两种编码格式,分别是rawtypes和 typedbytes,你可以设计你想采用的格式,这两种编码规则如下(具体在文章“Hadoop Streaming高级编程”中已经介绍了):
rawbytes:key和value均用【4个字节的长度+原始字节】表示
typedbytes:key和value均用【1字节类型+4字节长度+原始字节】表示
本文将采用第一种编码格式进行说明。采用这种编码意味着你不能想文本数据那样一次获得一行内容,而是依次获得key和value序列,其中key和value都由两部分组成,第一部分是长度(4个字节),第二部分是字节内容,比如你的key是dongxicheng,value是goodman,则传递给hadoop streaming程序的输入数据格式为11 dongxicheng 7 goodman。为此,我们编写下面的Mapper程序解析这种数据:

其中,辅助函数实现如下:

该程序需要注意以下几点:
(1)注意大小端编码规则,解析key和value长度时,需要对长度进行字节翻转。
(2)注意循环结束条件,仅仅靠!cin.eof()判定是不够的,仅靠这个判定会导致多输出一条重复数据。
(3)本程序只能运行在linux系统下,windows操作系统下将无法运行,因为windows下的标准输入cin并直接支持二进制数据读取,需要将其强制以二进制模式重新打开后再使用。
3. 程序测试与运行
程序写好后,第一步是编译C++程序。由于该程序需要运行在多节点的Hadoop集群上,为了避免部署或者分发动态库带来的麻烦,我们直接采用静态编译方式,这也是编写Hadoop C++程序的基本规则。为了静态编译以上MapReduce程序,安装protocol buffers时,需采用以下流程(强调第一步),
./configure –disable-shared
make –j4
make install
然后使用以下命令编译程序,生成可执行文件ProtoMapper:
g++ -o ProtoMapper ProtoMapper.cpp person.pb.cc `pkg-config –cflags –static –libs protobuf` -lpthread
在正式将程序提交到Hadoop集群之前,需要先在本地进行测试,本地测试运行脚本如下:

注意以下几点:
(1)使用stream.map.input指定输入数据解析成rawbytes格式
(2) 使用-jt和-fs两个参数将程序运行模式设置为local模式
(3)使用-inputformat指定输入数据格式为SequenceFileInputFormat
(4)使用mapred.reduce.tasks将Reduce Task数目设置为0
在本地tmp/output111目录下查看测试结果是否正确,如果没问题,可改写该脚本(去掉-fs和-jt两个参数,将输入和输出目录设置成HDFS上的目录),将程序直接运行在Hadoop上。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。