大数据时代,研究大数据的IT 厂商把研究重心放在优化大数据系统软件架构、优化业务逻辑、优化数据分析算法、优化节点性能等方向,而忽略了大数据环境基础设置中网络环节的评估和优化。本文介绍了思科公司在Hadoop 集群环境下的网络架构设计与优化经验。大数据
大数据时代,研究大数据的IT 厂商把研究重心放在优化大数据系统软件架构、优化业务逻辑、优化数据分析算法、优化节点性能等方向,而忽略了大数据环境基础设置中网络环节的评估和优化。本文介绍了思科公司在Hadoop 集群环境下的网络架构设计与优化经验。
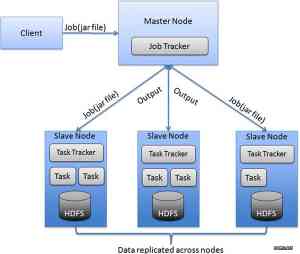
大数据Hadoop环境网络特性Hadoop 集群中的各节点通过网络连接起来,而且MapReduce 中的以下过程会在网络中传输数据。
写数据。当向HDFS 写入初始数据或者大块数据时,会发生数据写入过程。写入的数据块需要备份到其他节点,需要在网络中传输这些数据。
Map 阶段。在算法的Map 阶段,几乎不需要在网络中传输数据。在Map 开始阶段,当HDFS 数据没有本地性(数据块不在本地存储,需要从其他节点拷贝)时,才需在网络中传输数据。
Shuffle 阶段。这是作业执行中在网络中传输数据的阶段,数据传输的程度依赖于作业。Mapper 阶段的输出内容,会在这个时候传输到Reducer 进行排序。
Reduce 阶段。因为Reducer 需要的数据已经从Shuffle 阶段传来,所以此阶段不需要网络传输数据。
Output 复制。MapReduce 的输出作为文件存储在HDFS 上。当将输出结果写入HDFS 时,产生的备份会在网络中传输。
读数据。当应用程序如网站、索引或者SQL数据库从HDFS 读取数据时,会发生数据读取的过程。另外,网络对Hadoop 的控制层非常重要,比如HDFS 的信令和运维操作,以及MapReduce 架构都受到网络影响。
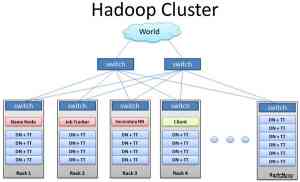
思科公司针对Hadoop 集群环境下的网络环境进行了一个测试,测试结果显示,一个有弹性的网络对Hadoop 集群非常重要;对Hadoop 集群具有重要影响的网络特性,以其影响程度从大到小依次排序为:网络可用性和弹性、Burst 流量突发处理和队列深度、网络过载比、Datanode 网络接入和网络延迟。
网络可用性和弹性。要部署一个高冗余性和可扩展的网络,支持Hadoop 集群的增长。在Datanode之间部署多条链路的技术要比那些有单点失效或两点失效的技术要好。交换机和路由器已经在业界被证明能够为服务器提供网络可用性。
Burst 流量突发处理和队列深度。HDFS 的有些操作和MapReduce Job 会产生突发流量,如向HDFS加载文件或者把结果文件写入HDFS 都需要通过网络。网络如果处理不了突发流量,就会丢弃数据包,所以适当的缓存可以缓解突发流量的影响。确保选择使用缓存和队列的交换机和路由器,来有效处理流量突发。
网络过载比。一个好的网络设计需要考虑到网络中关键节点的拥塞情况。一个ToR 交换机从服务器接收20Gbps 的数据,但是只有2 个1Gbps 的上联口会造成数据包丢失(10:1 的过载比),严重影响集群的性能。过度配置的网络的价格又非常昂贵。一般情况下,服务器接入层可以接受的过载比在4:1 左右,接入层和汇聚层之间,或者核心层的过载比在2:1左右。
Datanode 网络接入。要基于集群工作负荷来推荐带宽配置。一般集群中的节点有1 到2 根1GB 的上联口。是否选择10Gbps 的服务器要权衡价格和性能。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。










