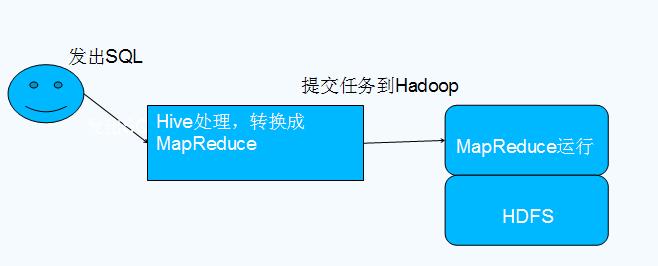
Hive是基于Hadoop的一个数据仓库工具,本质是将SQL转换为MapReduce程序,操作接口采用类SQL语法,提供快速开发的能力,Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
什么是Hive
•Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
•本质是将SQL转换为MapReduce程序

为什么使用Hive
面临的问题
人员学习成本太高
项目周期要求太短
我只是需要一个简单的环境
MapReduce 如何搞定
复杂查询好难
Join如何实现
为什么要使用Hive
•操作接口采用类SQL语法,提供快速开发的能力
•避免了去写MapReduce,减少开发人员的学习成本
•扩展功能很方便
Hive的特点
•可扩展
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务
•延展性
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
•容错
良好的容错性,节点出现问题SQL仍可完成执行
Hive与Hadoop的关系
Hive与传统数据库对比
|
|
Hive |
RDBMS |
|
查询语言 |
HQL |
SQL |
|
数据存储 |
HDFS |
Raw Device or Local FS |
|
执行 |
MapReduce |
Excutor |
|
执行延迟 |
高 |
低 |
|
处理数据规模 |
大 |
小 |
|
索引 |
0.8版本后加入位图索引 |
有复杂的索引 |
Hive的历史
•由FaceBook 实现并开源
•2011年3月,0.7.0版本 发布,此版本为重大升级版本,增加了简单索引,HAING等众多高级特性
•2011年06月,0.7.1 版本发布,修复了一些BUG,如在Windows上使用JDBC的的问题
• 2011年12月,0.8.0版本发布,此版本为重大升级版本,增加了insert into 、HA等众多高级特性
•2012年2月5日,0.8.1版本发布,修复了一些BUG,如 使 Hive 可以同时运行在 Hadoop0.20.x 与 0.23.0
•2012年4月30日,0.9.0版本发布,重大改进版本,增加了对Hadoop 1.0.0的支持、实现BETWEEN等特性
Hive的未来发展
•增加更多类似传统数据库的功能,如存储过程
•提高转换成的MapReduce性能
•拥有真正的数据仓库的能力
•UI部分加强
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。










