人工智能推动的巨大数据增长将使卸载的数据完整性检查成为必要,而不仅仅是锦上添花。
人工智能 (AI) 大型语言模型和其他形式的深度学习已经需要大量的训练数据。随着越来越多的组织实施人工智能,预计数据量将增长。这种情况引入了新的系统瓶颈(计算、内存和 I/O),并引发了对静默数据损坏的真正风险的新担忧。组织不想在构建 AI 模型时质疑其训练数据的完整性。
传统上,执行数据完整性检查由 CPU 执行,但这些检查需要时间。最好在后台持续执行这些检查,这一过程称为数据清理,以最大程度地减少应用程序中断。理想情况下,损坏的数据会在应用程序需要之前修复。然而,在实践中,这些完整性检查通常不经常运行,或者更糟糕的是,由于成本原因,这些完整性检查完全被禁用。
为了解决日益增长的静默数据损坏问题,英特尔研究院积极参与研究,以使用计算存储 (CS) 解决数据完整性问题。英特尔研究院首席工程师 Michael Mesnier 表示:“数据清理卸载是计算存储的一个实际用例,因为它有助于减少数据移动瓶颈以及计算、内存和 I/O 的相关压力。大多数存储设备已经内置了用于检查数据完整性的加速器,包括 CRC-64 等校验和算法,但这些加速器没有文件感知功能。他们只看到块。在这些设备中执行端到端文件校验和需要计算存储技术。
计算存储如何协助数据完整性检查?
- 减少 I/O 和相关处理正是计算存储背后的动机,因此数据清理代表了一个真实的用例。检查一个文件的完整性涉及:
- 正在读取文件。 计算文件的校验和(或哈希值)。 将其与以前存储的校验和进行比较。
- 如果校验和一致,则文件的完整性没有受到损害。如果校验和不一致,则文件自上次写入以来已损坏,必须重建(例如,使用复制或擦除编码)。
组织必须在其整个数据集上完成此过程。这是一个读取密集型工作负载,您可以在其中从存储集群中的每个驱动器上的每个文件系统中读取每个文件。如果不加以控制,它将是一个应用程序杀手,因为它会消耗所有可用的 I/O 并增加主机 CPU 和内存的负载。
Mesnier指出,这就是计算存储可以提供帮助的地方。通过将数据完整性检查卸载到块存储,可以原位(在单个 SSD 或存储服务器内)执行检查,并且可以节省与处理 I/O 和在主机 CPU 上运行完整性检查相关的成本。但这必须端到端地完成。端到端文件校验和对于数据完整性至关重要,因为在数据到达驱动器之前,软件(应用程序、操作系统、设备驱动程序)、CPU、内存或 I/O 层可能会发生静默损坏。最佳做法是在创建新数据时尽可能高地计算堆栈中的校验和,这通常是在文件级别完成的。
正如 Mesnier 所指出的,存储服务器和 SSD 已经具有各种用于完整性检查的内置引擎,但这些引擎仅在块级别执行,而不是对整个文件进行端到端执行。因此,卸载完整性检查首先需要我们向块存储传授有关“文件”的知识以及如何执行端到端文件校验和,这些校验和可能分散在存储设备的许多区域中。如果没有计算存储技术,存储设备就无法直接处理主机的文件,因为它缺乏数据感知能力。存储设备只能看到扇区(硬盘驱动器)或页面 (SSD),而看不到文件和目录。
英特尔研究院计算存储研究平台
英特尔研究院的研究人员 创建了一个研究平台(目前可供客户和合作伙伴使用),以教授块存储如何查看主机数据结构(如文件),并随后处理数据。“这使我们能够应对计算存储的挑战并探索各种用例。我们的研究平台基于 NVMe 协议,将计算功能移动到存储服务器(例如 NVMe/TCP)或单个 SSD。这种方法与通过计算存储阵列 (CSA) 或计算 SSD (CSD) 提供计算存储功能 (CSF) 的行业标准编程模型非常吻合。在这两种情况下,将工作卸载到存储都可以减少主机的 CPU 负载、内存占用、I/O,以及在 CSA 的情况下减少网络流量,“Mesnier 说。
正如他们的热存储论文中首次描述 的那样,该方法基于虚拟对象。 实际上,虚拟对象允许主机与存储共享文件元数据(例如,块映射和文件大小)。这种方法允许存储“看到”文件并将其读入存储本地内存以进行后续处理。虚拟对象与要执行的操作列表一起嵌入在计算描述符中(例如,搜索、筛选、哈希、校验和)。这些计算描述符使用新的 NVMe 命令发送到存储。
各种软件层构建在虚拟对象机制之上,如下图所示。
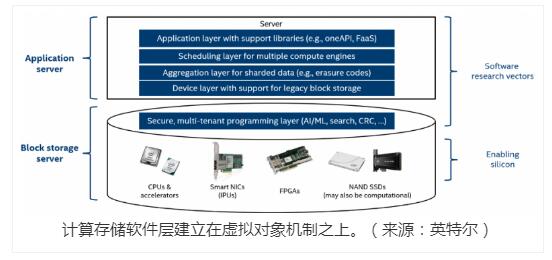
计算存储软件层建立在虚拟对象机制之上。(来源:英特尔)
应用层提供了一个方便的基于文件的界面,并抽象出大多数计算存储细节。 应用程序只需请求对文件执行操作(例如,搜索、过滤、哈希、校验和)。 同一层可以与其他计算层连接,如英特尔的 oneAPI 和 FaaS.
调度层用于跨资源进行最佳调度。聚合层有助于处理分布在多个存储设备上的数据,纠删码数据就是这种情况。最后,设备层通过创建计算存储命令和直接与 CSA 和 CSD 的接口来与 NVMe 进行通信。
就 CSA 而言,英特尔实验室还有一个额外的层,用于虚拟化和管理计算资源。此层为安全的多租户编程环境奠定了基础。在此块存储服务器中,使用各种芯片和系统软件来加速计算和 I/O 密集型操作。该解决方案使用支持 CRC-64(通过数据流加速器)的英特尔®至强®处理器,这是对损坏数据的强大端到端检查。
英特尔研究院一直在使用该平台进行研究和生态系统支持.
构建生态系统
计算存储将需要强大的生态系统支持,英特尔研究院正在积极与 IHV(独立硬件供应商)和 ISV(独立软件供应商)合作。IHV 参与位于堆栈的底部(设备层),ISV 参与位于顶部(应用程序层)。
这项任务涉及与固态硬盘供应商(包括 Solidigm)密切合作,以构建针对英特尔服务器平台优化的 CSD 原型。Solidigm 的 Scott Shadley(长期战略总监)表示:“Solidigm 的 PoC CSD 基于第 5 代 SSD 产品,其中包括用于数据完整性计算的低成本、高效率和高性能 ASIC。我们期待与英特尔合作,优化服务器平台的解决方案,并将其集成到完整的 E2E 软件堆栈中。
在堆栈的顶端,英特尔实验室一直在与 MinIO 合作,从数据清理卸载开始,为他们的堆栈启用计算存储。去年在闪存峰会和SNIA的存储开发者大会上展示了这项合作工作的早期演示.
Mesnier 表示,英特尔实验室还与 SNIA 合作开发和评估计算存储使用模型。SSD 供应商可以通过 TP4091 使用其基于 NVMe 的堆栈进行原型设计和最终标准化。
英特尔实验室未来的计算存储工作
几十年前,计算存储已经有许多错误的开始,该行业仍然缺乏广泛的用例。 根据 Mesnier 的说法,“我们相信数据清理可以成为这样的用例。人工智能推动的巨大数据增长将使卸载的数据完整性检查成为必要,而不仅仅是锦上添花。随着广泛用例的到位,英特尔研究院相信该生态系统将成熟并成为其他用例的基础。用于数据清理的相同计算存储协议可以在堆栈中更高,以加速其他操作,如 AI(训练和推理)和大数据(排序、搜索、过滤)。英特尔研究院期待计算存储带来的机遇,并积极邀请其他公司进行合作。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。