笔者对几种多控高端存储下的缓存一致性管理、缓存镜像管理等方面做简要分析,并以浪潮AS18000高端存储系统为例来实际分析。
高端IT系统的缓存管理一直是个极具挑战性的课题,从计算领域到存储领域,该问题普遍存在。
比如,多核心多CPU体系中的分布式L1/2/3缓存的一致性管理,而随着从SMP到NUMA的演进,NUMA架构下的分布式缓存管理更是增加了CPU内硬件的复杂度。在存储领域,全对称多活多控制器存储系统从一开始便普遍使用集中式的数据缓存来保证缓存一致性。
本文中,笔者对几种多控高端存储下的缓存一致性管理、缓存镜像管理等方面做简要分析,并以浪潮AS18000高端存储系统为例来实际分析。
1. 多控高端存储系统的缓存管理的几种方式
1.1 集中式缓存管理
在这种缓存管理模式下,集群中所有节点均不维护本地缓存,而是所有节点共享访问一个集中存放的缓存,数据在缓存中只有一份副本,不会也不可以出现多份副本。在计算领域,典型例子比如单颗CPU芯片内的多个核心共享的LLC(LastLevel Cache)。在存储领域,典型例子则是某些厂商的高端存储系统中所使用的集中式缓存,比如下图架构所示:
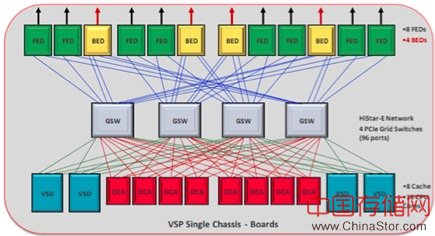
集中式缓存一致性管理
该缓存管理架构的优点是天然的缓存一致性,因为不存在多个副本,不需要特殊过程来维护缓存一致性。对于高端存储系统而言,该设计的劣势则是需要缓存集中放置,需要使用某种外部网络来连接集中的缓存,而且提供异步化的类似IO的访问方式,编程复杂,难以掌控和优化,需要投入大量成本。
1.2 任意关联对称式分布式缓存
所谓分布式缓存,指的是集群中的每个节点都有自己独享的缓存,这种情况会给缓存一致性管理上带来极大的复杂性,当然,所获得的收益便是一旦命中则性能会非常好。所谓对称式指的是集群中所有节点在缓存管理的地位上是均等的,都可以自行控制管理各自的缓存。所谓任意关联,则是指任意节点均可以缓存任意数据块,数据块大小视不同产品设计而定,比如多CPU集群的缓存数据块大小为一个缓存行,Cache Line,一般为64Byte大小。而对于高端存储系统,则一般以4K及其整数倍为粒度。
因为可以任意缓存,所以会导致多个集群节点同时缓存有同一个数据块的多个不同版本的副本,从而导致一致性问题。解决的办法则是效仿多CPU缓存一致性管理方面的思路,采用MESI一致性基本协议及其变种,可以在尽量减少广播通信的前提下实现任意关联分布式缓存一致性。
该设计的优点则是可以充分利用缓存空间,且学院派高逼格凸显。劣势则是成本高,因为需要一个低时延的网络来实现MESI协议流量,否则性能将很差;另外,需要一个高速搜索算法来搜索对应目标数据块在缓存中的位置,必要时引入硬加速比如TCAM等,成本再次增加。
1.3 固定关联对称式分布式缓存
相比上一种实现方式,固定关联的思想则是通过牺牲缓存利用率来降低广播流量,换取性能。固定关联指的是集群中的节点不能缓存任意数据块,而是每个节点只能缓存部分数据块,比如,可以按照对应Lun ID+LBA地址段的hash值来索引集群节点,索引到谁就缓存在谁那里,并且只有单一的副本。其他节点如果接收到访问该LBA段的读IO请求,则需要通过网络向用用该LBA段缓存的节点发出请求,获取数据;对于写,也是一样,必须将数据转发到有权限缓存该段LBA的节点,自己不能缓存。

固定关联对称式分布式缓存
这样做的优势在于能够避免缓存一致性问题,因为只有一份副本。劣势在于极端条件下可能导致缓存利用不均衡,因为数据块与其缓存位置是一一对应的,可能导致某些节点缓存空余很多,而某些则近满。
2. 浪潮AS18000高端存储的缓存管理技术
AS18000是浪潮的一款高端存储系统,其在架构上与北美厂商的高端存储产品有着本质区别,也正是这种架构成就了该系统相对更高的可靠性。
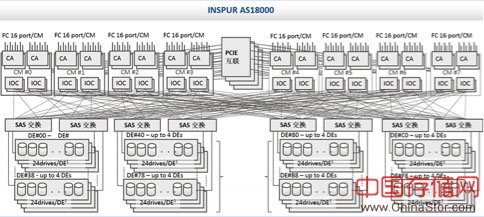
AS18000架构
AS18000最大支持16个控制器,每个控制器可以支持12-144GB的本地缓存。在AS18000中,虽然缓存物理依附于本地控制器,但是存储系统启动之后,各个控制器的本地内存将组合为一个全局的缓存逻辑视图。也就是说每个控制器都可以“看到”整个逻辑视图。
全局的逻辑视图可以让每个控制器站在全局的高度来“审视”存储中的LUNOwener、路由链路等资源信息,减少决策和仲裁耗时。
2.1 AS18000缓存一致性管理
AS18000并没有将数据缓存分拆且集中存放,本地CPU访问本地RAM依然使用DDR接口高速率访问,同时本地CPU也可以访问其他节点的RAM,此时则通过PCIE Switch的NTB桥方式,将各个节点的一部分内存相互映射到本地,本地控制器将需要同步给远端的消息、数据写入本地的这块内存空间,底层硬件就会自动将这些消息向目标端传递。
经过这样的设计,其访问效率就不会向集中缓存方式的高端存储那样低下。AS18000采用的是固定关联方式,其关联粒度为一个Raid Group,也就是说,某个Raid Group中的全部数据只能缓存在某个节点,这样做的目的是充分保证缓存的局部性,避免跨网络交换数据,从而保证系统的性能。对于高端存储系统所处的应用环境,都是少量核心关键业务,所以,缓存的整体利用率并不是问题,此时保证性能的稳定无抖动,不跨网络保证时延最低,才是最关键的考量点。
除了在缓存一致性方面的优良设计之外,浪潮AS18000在后端的存储介质管理方面采用的则是全对称式后端共享架构,能够在保证性能的前提下,极大提升系统的可靠性及扩展性。这也是为何该架构如今仍然生命力顽强,而其他的架构已经陨落的原因之一。

2.2 AS18000写缓存管理
在AS18000系统中,缓存是全局的,但缓存的读、写操作都只能被各自的控制器所控制,也就是说,其它的控制器需要读、写非Owner 的LUN数据,只能通过前端路由(BRT)发出指令给相应具有Owner的控制器,由具有Owner权限的控制器处理完成读、写操作之后,将数据或者ACK返回给发起端控制器。
如前文所述,每个控制器都具有本地的物理缓存,存储系统启动后,缓存空间将被初始化为多个page,当控制器发起读操作后,数据将从磁盘load到page中,如果此page中的数据发生了变化,此page将会标记为dirty page(只有标记为dirty page的缓存区间才会被写入)。dirty page并不会马上写入到硬盘中,而是会加入dirty chain表中,chain表会根据先进先出原则发出写指令,也就是说多个dirty page会一同被写入到磁盘。
2.3 AS18000缓存镜像管理
写缓存镜像是任何传统存储系统必须实现的功能。为了防止某节点突然宕机且由于各种原因无法成功重启,写入任何节点缓存的数据必须被镜像一份到其他节点作为临时备份,当数据被写盘后,便将临时备份删除。
AS18000存储缓存中的dirty page将自动镜像到相邻的控制器缓存中。其工作流程如下:具有Owner权限的控制器的缓存空间发生变化,变为了dirty page,此时控制器将发起copy dirty page进程,通过前端路由(BRT)将此dirty page复制到相邻的控制器缓存中,此时两个控制器中的dirty page完成mirror,相邻控制器返回ACK应答后,主控器中的dirty page将page index连接到dirty chain表中,然后由dirty chain表发出write操作,落入磁盘的dirty page并不会马上删除,而是会标记为clean page,可承载后续的读操作。

隔离链式环形缓存镜像技术
AS18000采用隔离链式环形缓存镜像技术,如上图所示,假设系统有4个节点(Control Module)组成,CM0的写缓存会被镜像到CM1,CM1则到CM2,CM2到CM3,然后CM3的写缓存再被环回镜像到CM0。
综上所述,浪潮AS18000高端存储系统在缓存管理方面创新较多,技术优势不容小觑。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。