POLARDB是基于第三代云计算架构下的商用关系型云数据库产品,POLARDB单实例的读性能达到了100万QPS,高出AWS Aurora一倍;写性能达到了13万TPS.
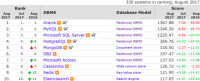
大屏幕上正在显示着一场云数据库现场测试的实时结果:POLARDB单实例的读性能达到了100万QPS,高出AWS Aurora一倍;写性能达到了13万TPS,同样遥遥领先;过去需要要70个小时的10TB的业务数据创建只读副本,在POLARDB上只需2分多钟,全球范围创建容灾实例时间也是一样。
对于这样的实测结果,江湖人称“霸爷”的阿里云数据库掌门人褚霸(余锋)并不感到意外。
POLARDB是基于第三代云计算架构下的商用关系型云数据库产品,经过褚霸团队三年研发,凝结了数十位阿里云工程师的心血——它实现了对MySQL的100%兼容,达到了当前云数据库实例的最高规格(64核/512GB),并达到了100TB的存储容量。
“兼容性、性能、存储容量,我们认为这三点非常重要,这三点可能是最朴素的,但这三点是最难解决的,解决了这三点就解决了99%问题”,褚霸解释说。

阿里云数据库掌门人褚霸(余锋)
相比国际顶尖的竞争对手,阿里云POLARDB已经取得了量级上的优势,看上去这个新发布的云数据库已经“解决了99%的问题”,然而褚霸并不甘心于此。
POLARDB被定义为一款“商用”、“关系型”数据库,其目标自然不仅是MySQL,矛头同时也指向了传统的Oracle等商用关系型数据库。
“以开源数据库的价格去获取商业数据库的品质”,是褚霸对于这款POLARDB云数据库更深层次的期望。
从A点到B点
在很多营销教科书上,都有着这样一个经典的案例,是关于福特汽车和马的故事。
“如果我最初问消费者他们想要什么,他们应该是会告诉我,‘要一匹更快的马!’”,100多年前,亨利·福特曾经这样总结客户的需求。
然而,福特并没有去给客户准备更快的马,而是去制造汽车。因为福特真正洞悉到客户需要一匹更快的马的真正用意是“用更短的时间、更快地到达目的地。”。
“Oracle等大厂商其实花了很多时间在教育客户上面,让用户忘了最初的目的”,谈及阿里云设计POLARDB的初衷,褚霸说的很直接。
商用关系型数据库发展至今,已经有四十余年的历史,期间有着几个标志性的事件。
1976年,霍尼韦尔公司(Honeywell)开发出第一个商用关系数据库系统——MulticsRelational Data Store。从那时起,数据库就开始改变人类对数据的管理和认知,发展到如今诸如登录淘宝购物、社交软件聊天,都离不开数据库。
上世纪70年代末,第一代Oracle数据库问世。1983年,C语言刚刚推出不久,Oracle的第三版产品就用C语言进行了改写,从而具有了很好的可移植性,在商用关系型数据库市场上占据了先机。如今,Oracle数据库已经发展到12c版本,如今,不仅大量传统行业和企业都在应用Oracle数据库,国内大部分云厂商提供的数据库服务也仍采用这种技术架构。
1996年,MySQL 1.0发布,最初的版本只有少数几个功能。2000年,MySQL正式进入开源世界,从此发展驶入了快车道。如今MySQL已经成为全球最受欢迎的开源数据库,不仅在互联网企业中得到大量应用,并被很多传统企业视为Oracle数据库的理想取代品之一,其市场份额一直高居前三。
Oracle和MySQL,分别已经站到了商用和开源数据库世界的顶点,然而随着互联网时代来袭,大数据爆棚,这两个各自领域的王者也显得有些力所不及。
Oracle数据库采用本地存储模式,但磁盘容量是一个固定值,一旦遇到磁盘容量用完情况,则需通过采购新服务器解决,企业IT成本将随之攀升。而摆在MySQL面前的问题是,随着互联网发展,企业数据爆炸,其性能问题逐渐暴露,互联网大数据存储以及高并发场景一直成为MySQL数据库无法逾越的鸿沟。
——在互联网时代,企业将不得不面对海量数据存储、高并发等场景,传统数据库虽然稳定但成本高,而开源数据库又一直无法解决性能瓶颈问题。那么,客户该如何做出抉择和取舍?相信对于大多数客户来说,他们并不知道如何来选择数据库,也不知道如何来优化数据库来应对新的业务挑战,他们只希望“用更短的时间、更快地到达目的地。”
这正是阿里云耗费三年,投入大量心血来自研一款云数据库的缘由。
“POLARDB云数据库就是以开源数据库托管的价格提供商业数据库的性能和可靠性,让客户最快的达到目的——从A点到B点”,褚霸表示。
POLARDB采用第三代分布式共享存储架构,实现计算节点和存储节点分离,使计算引擎和存储引擎均拥有快速扩展能力,相对于传统数据库,云数据库实现高性能、高容量兼具低成本特性,为互联网海量数据以及超高并发场景而生。得益于第三代分布式共享存储架构,使POLARDB实现100T级别数据库容量、6倍于MySQL性能、与开源数据库持平的使用成本。
在褚霸看来,客户需要的是能力,是服务,而不是选择什么样的数据库;云计算则赋予了阿里云重新定义数据库的机会。
三个问题,三个目标
“如何更好的利用硬件红利?”
“如何以开源数据库的价格去获取商业数据库的品质?”
“如何数据库的快速迭代和服务?”
这是阿里云数据库掌门人褚霸总结出的三个数据库行业难题,也是给POLARDB设置下的三个目标。
于是,阿里云POLARDB首先在硬件规格上做到了极致:支持最大100T的存储容量,采用64核CPU(3.0GHz ,Skylake CPU)及512GB内存,超过同行一倍。使用高达50Gbps的RDMA网络来连接其分布式计算节点集群,采用NVMe SSD,单盘吞吐量达到32Gb/s。
“单单硬件牛就够了么?其实不够,如果有钱,硬件都可以去买,如何把它们最有效的用起来才是最重要的事”,褚霸认为。
云数据库产品的存储方式经历了三代:第一代是本地盘存储,国内大多数云厂商的数据库服务都采用这种方式;第二代是集中式存储,阿里云自身的数据库服务以及国外云厂商的数据库服务采用的是这种方式;第三代是分布式共享存储,阿里云POLARDB、AWS Aurora采用的是这种方式。
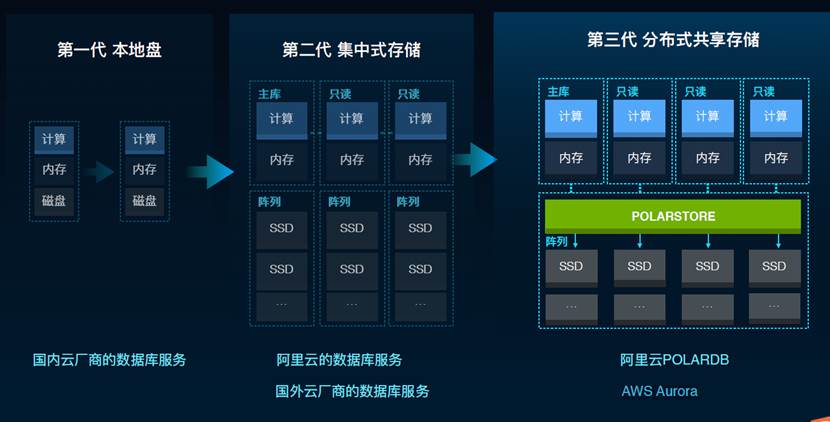
首先,受益于第三代分布式共享存储架构,POLARDB实现了计算节点(主要做SQL解析以及存储引擎计算的服务器)与存储节点(主要做数据块存储,数据库快照的服务器)的分离,提供了即时生效的可扩展能力和运维能力。
众所周知,在传统数据库上做扩容、备份和迁移等操作,花费的时间和数据库的容量成正比,往往上TB的数据库容量加个只读副本就需要一到两天时间。POLARDB的存储容量可以实现无缝扩展,不管数据量有多大,2分钟内即可实现只读副本扩容,1分钟内即可实现全量备份,为企业的快速业务发展提供了弹性扩展能力。
其次,与传统云数据库一个实例一份数据拷贝不同,POLARDB同一个实例的所有节点(包括读写节点和只读节点)都实现访问存储节点上的同一份数据,使得POLARDB的数据备份耗时实现秒级响应。(备份时间与底层数据量无关)
最后,借助优秀的RDMA网络以及最新的块存储技术,实现服务器宕机后无需搬运数据重启进程即可服务,满足了互联网环境下企业对数据库服务器高可用的需求。
除了硬件、存储架构上的优化以外,褚霸团队最拿手的是“做引擎”,过去几年阿里云数据库团队在数据库引擎层面的积累在POLARDB上厚积薄发。
“POLARDB在高并发上做了连接池,性能上提升50%;在单表性能上也做了大的改进,比如说在多核里面性能最大的杀手是锁,我们在锁上进行了大量的优化,单表性能提升70%。我们会优化SQL,读性能提升10%,类似于这样的优化很多”,褚霸举例说。

结合多方面的创新要素,POLARDB实现了MySQL六倍的性能,并让褚霸团队有了POLARDB云数据库进行现场“跑分”的底气。“没有金刚钻,不揽瓷器活”,褚霸得意的说。
在今年8月的时候,阿里云首次放出了POLARDB的消息。其中一条关键的特征即“它拥有商业数据库一样的性能,但价格仅为前者的1/10,进一步降低用户的上云成本”。
商业数据库的性能,价格仅有十分之一,这对需要为商业数据库付出高昂成本的用户来说无疑极具吸引力。
POLARDB采用了一种计算和存储分离的架构,两个资源池都可以按需扩容。而传统的数据库部署模型则是一种烟囱模型,CPU和磁盘的配比主要取决于实际业务的需求,很难提前找到最优比例;同时传统数据库由于磁盘碎片问题,导致磁盘使用率低。“POLARDB通过存储资源池化,这两个问题都能得到解决,SSD的利用率得到提高,成本自然也降低下来。”
POLARDB还具有一个“透明压缩”功能。存储节点除了对ibd文件提供1MB的原子写,消除double write的开销,还支持对ibd文件的数据块进行透明压缩,压缩率可以达到2.4倍,进一步降低了存储成本。
此外,针对传统数据库只读实例耗时、昂贵的难题,POLARDB一方面新增只读实例不需要拷贝数据,不管数据量有多大都可以在2分钟内创建出来;另一方面,主实例和只读实例共享同一份存储资源,通过这种架构去增加只读副本,可以做到零新增存储成本,用户只需要支付只读实例消耗的CPU和内存的费用。
综合这些因素,POLARDB将数据库的成本大幅降低,而通过云的方式将数据库服务提供给用户,则是进一步帮助用户降低了应用数据库的成本。
在褚霸看来,云计算改变了软件迭代和服务的方式。云数据库则是一种PaaS服务,不仅软件的快速交付和迭代,阿里云所提供的可靠性、可用性同时也包含在这种云服务之中,未来POLARDB云数据库在功能和性能上的改进会通过云更快的推给客户。
据褚霸介绍,如今POLARDB已经100%向下兼容MySQL 5.6,很快将会兼容5.7和5.8版本。“MySQL社区发展很多年,整个数据库生态是非常完善。怎么样把传统数据库或者是生态迁移到云上,很重要一点就是兼容性。”在褚霸眼中,100%的兼容性和99%的兼容性并不是只差个1,而是“0”和“1”的区别,非黑即白。
或许正是这种偏执,让褚霸和他不过数十人的数据库团队能够在短短三年时间里,做出一个具有划时代意义的云数据库产品,给予商用关系型数据库一个全新的定义。
Hi,未来!
回到阿里云的这场POLARDB云数据库现场跑分测试。
在褚霸看来,关系型数据库单实例读性能达到50万是一个分水岭,50万之后则要涉及整个体系架构的改变,非常考验团队和产品的能力。
在现场跑分测试中,POLARDB单实例的读性能达到了100万QPS,对于褚霸及其数据库团队来说,这是一个极大的挑战,实现过程极其不易。
“POLARDB整个引擎会涉及到网络存储、虚拟化、数据路径等各种模块的优化,给我的感觉是好像要集齐7颗龙珠,我觉得每颗龙珠去获得都非常的不容易。”
困难并没有成为褚霸团队的绊脚石。在POLARDB的研发过程中,褚霸曾经用一系列的精彩描述来鼓舞团队士气:“这是一个团队安身立命的产品,是一个团队的远大理想,是一次殚精竭虑的创造,是一个团队不折不扣的担当!”
于是,这个团队成就了一个商用关系型数据库历史上划时代的产品——POLARDB是未来云数据库的雏形(All in one),一个数据库即可满足现时多类数据库混合使用效果。阿里云发挥自身自研能力优势,以POLARDB为产品契机,实现数据库OLTP与OLAP的一体化设计,为企业的数字化升级所需的IT设施架构实现了革命性进化。
也由此,在云计算市场里,云计算厂商今后将被划分为两类:一类是具备自研数据库能力的云计算厂商,另一类是提供其他数据库的云计算厂商。
但褚霸并不满足于此。
对于POLARDB来说,100万单实例QPS并不是终点,而是揭开了一个单实例百万QPS的时代。“我相信100万单实例QPS时代会因此开启,我相信后面越来越多的厂商进来,未来会有更高的数据会被刷新。”
如今,POLARDB已经开始公测,有基础版、高可用版、金融版三个版本。在褚霸看来,POLARDB未来还有着很大的成长空间,因为POLARDB承载着用户的价值。阿里云数据库团队还要不断创造更加优秀的产品,要把可靠性做到固若金汤。
“我们相信我们能做到,所以我们每一次需要做到最好,因为这个团队还能做到比难更难。因为众志成城,因为我们相信。”
据悉,2017阿里云栖大会将于10月11日~14日举行,阿里云数据库产品团队将在这次大会上持续发力,举办8大数据库专场,将技术红利再次深度释放,同时将宣布重磅产品升级和开源技术,回馈用户和社区。此外,还有业内知名数据库创始人、专家站台演讲。
对于阿里云数据库产品团队来说,这场云栖大会像是一场“沙场秋点兵”,也像是一个收获的节日。享受喜悦之后,这支队伍又将开启新的征程。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。