谷歌宣布推出其规模最大、功能最强大的新大型语言模型Gemini,其最强大的TPU“Cloud TPU v5p”以及来自谷歌云的人工智能超级计算机。

Google DeepMind首席执行官兼联合创始人Demis Hassabis称:Gemini 是 Google 各团队(包括我们在 Google 研究院的同事)大规模协作的结果。它是从头开始构建的多模态,这意味着它可以概括和无缝地理解、操作和组合不同类型的信息,包括文本、代码、音频、图像和视频。
谷歌DeepMind首席执行官德米斯·哈萨比斯表示,“我认为我们在32项基准中的30项中大幅领先。”
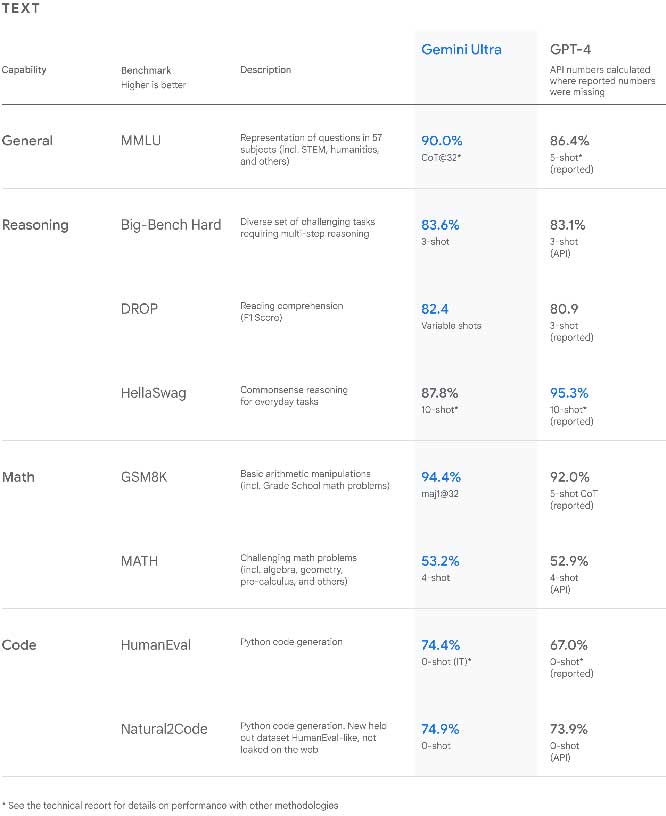
我们一直在严格测试我们的双子座模型,并评估它们在各种任务中的表现。从自然图像、音频和视频理解到数学推理,Gemini Ultra 在大型语言模型 (LLM) 研发中使用的 32 个广泛使用的学术基准中的 30 个方面,其性能超过了当前最先进的结果。
Gemini Ultra 的得分为 90.0%,是第一个在 MMLU(大规模多任务语言理解)方面优于人类专家的模型,MMLU 使用数学、物理、历史、法律、医学和伦理学等 57 个科目的组合来测试世界知识和解决问题的能力。
我们对 MMLU 的新基准方法使 Gemini 能够在回答困难问题之前使用其推理能力进行更仔细的思考,从而比仅使用其第一印象有显着改进。
当地时间12月6日,谷歌公司宣布推出其规模最大、功能最强大的新大型语言模型Gemini,其最强大的TPU(张量处理单元)系统“Cloud TPU v5p”以及来自谷歌云的人工智能超级计算机。v5p是今年早些时候全面推出的Cloud TPU v5e的更新版本,谷歌承诺其速度明显快于v4 TPU。
一年前,在人工智能开发机构OpenAI发布聊天机器人ChatGPT后,创造了当前人工智能热潮背后大部分基础技术的谷歌措手不及,一度发布了内部“红色警报”(red code)。一年零一周后,谷歌似乎准备好了反击。
谷歌DeepMind首席执行官、Gemini团队代表德米斯·哈萨比斯(Demis Hassabis)在发布会上正面谈及GPT-4与Gemini的对比,“我们对系统进行了非常彻底的分析,并进行了基准测试。谷歌运行了32个完善的基准测试来比较这两个模型,从广泛的整体测试(如多任务语言理解基准测试)到比较两个模型生成Python代码的能力。”哈萨比斯略带微笑地表示,“我认为我们在32项基准中的30项中大幅领先。”
从发布日起,Gemini可开始应用于Bard和Pixel 8 Pro智能手机,并将很快与谷歌服务中的其他产品集成,包括Chrome、搜索和广告等。
“Gemini Pro性能优于GPT-3.5”
大型语言模型Gemini包括一套三种不同规模的模型:Gemini Ultra是最大、功能最强大的类别,被定位为GPT-4的竞争对手;Gemini Pro是一款中端型号,能够击败GPT-3.5,可扩展多种任务;Gemini Nano用于特定任务和移动设备。
目前,谷歌计划通过谷歌云将Gemini授权给客户,供他们在自己的应用程序中使用。12月13日开始,开发者和企业客户可以通过谷歌AI Studio或谷歌Cloud Vertex AI中的Gemini API(应用程序编程接口)访问Gemini Pro,安卓开发人员可以使用Gemini Nano完成构建。
从发布会当天开始,谷歌聊天机器人Bard将使用Gemini Pro来实现高级推理、规划、理解和其他功能。明年初,谷歌将推出Bard Advanced,其将使用Gemini Ultra,这代表了Bard发布以来的最大更新。
从发布会当天开始,Pixel 8 Pro手机的两项功能将由Gemini Nano提供支持:录音机应用中的自动摘要功能以及Gboard键盘的智能回复部分。由于模型在手机中运行,因此两者都可以离线工作,因此应该能拥有快速且原生的体验。谷歌表示,Nano的目标是创建一个尽可能强大的Gemini版本,但同时不会占用手机的存储空间或使处理器过热。
据介绍,Gemini Ultra是第一个在MMLU(大规模多任务语言理解)方面超越人类专家的模型,该模型综合使用数学、物理、历史、法律、医学和伦理学等57个科目来测试世界知识和解决问题的能力,谷歌在一篇博客文章中表示,它可以理解复杂主题中的细微差别和推理。
据哈萨比斯介绍,在对比Gemini和GPT-4的基准测试中,Gemini最明显的优势来自于它理解视频和音频并与之交互的能力。这很大程度上是设计使然:多模态在最开始就是Gemini计划的一部分。谷歌没有像OpenAI构建DALL·E(文生图模型)和Whisper(语音识别模型)那样单独训练图像和语音模型,而是从一开始就建立为一个多感官模型。
而据CNBC报道,谷歌高管们在新闻发布会上表示Gemini Pro的表现优于GPT-3.5,但回避了与GPT-4相比如何的问题。对于谷歌是否计划对Bard Advanced的访问收费,Bard总经理萧茜茜(Sissie Hsiao)表示,谷歌专注于创造良好的体验,目前还没有任何相关盈利的细节。
“我们一直对非常通用的系统感兴趣。”哈萨比斯说,他对如何混合所有这些模态特别感兴趣,“从任意数量的输入和感知中收集尽可能多的数据,然后给出尽可能多的响应。”
Gemini最基本的模型是文本输入和文本输出,但更强大的模型(如Gemini Ultra)可以处理图像、视频和音频。哈萨比斯说,它甚至会变得更加通用,有像动作和触摸之类更像机器人类型的东西。他认为,随着时间的推移,Gemini将获得更多的感知,变得更有意识,并在这个过程中变得更加准确和稳定。“这些模型只是更好地了解周围的世界。当然,这些模型仍然存在幻觉,并且仍然存在偏见和其他问题。”但哈萨比斯表示,它们知道的越多,就会做得越好。
谷歌似乎特别将编程视为Gemini的杀手级应用程序,它使用了一种名为AlphaCode 2的新代码生成系统,据称该系统的性能优于85%的编程竞赛参与者,而原始AlphaCode的这一比例为50%。
谷歌首席执行官桑达尔·皮查伊(Sundar Pichai)表示,用户会注意到模型涉及的几乎所有方面都有所改进。
“不愿为了跟上步伐而走得太快”
值得注意的是,今年5月,包括哈萨比斯在内的500多名著名学者和行业领袖签署的一份声明称,“与流行病和核战争等其他社会规模风险一样,减轻人工智能带来的灭绝风险应该成为全球优先事项。”
在这次发布会中,哈萨比斯和皮查伊对于谷歌似乎步调缓慢的说法回应道,他们不愿意为了跟上步伐而走得太快,“尤其是当我们越来越接近人工智能的终极梦想‘通用人工智能’时”。“当我们接近通用人工智能时,事情将会有所不同。”哈萨比斯说,“这是某种具有主动性的技术,所以我认为我们必须谨慎对待,谨慎但乐观。”
谷歌表示,通过内部和外部测试以及警示团队(red-teaming),它一直在努力确保Gemini的安全和责任。皮查伊指出,确保数据的安全性和可靠性对于企业优先的产品尤为重要,这也是大多数生成式人工智能利润的来源。与此同时,哈萨比斯也承认,推出最先进的人工智能系统的风险之一就是,它会出现没人能预测到的问题和攻击向量(attack vector)。“这就是为什么你必须释放一些东西,去观察和学习。”他说。
谷歌发布Gemini Ultra的速度较慢,哈萨比斯把它比作一个可控的测试版,为这个谷歌最强大、最不受约束的模型提供了一个“更安全的试验区”。“基本上,如果Gemini有一个破坏婚姻的另类人格,谷歌会在你之前找到它。”这番话影射了此前微软必应聊天机器人向《纽约时报》专栏作家凯文·卢斯(Kevin Roose)求婚,并试图拆散他的婚姻。
上周,The Information报道称,因为人工智能“无法可靠地处理一些非英语查询”,所以谷歌原定于本周举行的Gemini现场演示被无限期推迟。在回答有关外语问题的问题时,谷歌DeepMind产品副总裁艾力·柯林斯(Eli Collins)表示:“事实上,Gemini在多语言能力方面表现相当出色。”
谷歌最强TPU与AI超级计算机
与新模型一起亮相的,还有新版本的TPU芯片TPU v5p,旨在减少训练大语言模型相关的时间投入。TPU是谷歌为神经网络设计的专用芯片,经过优化可加快机器学习模型的训练和推断速度,谷歌于2016年起开始推出第一代TPU。
据谷歌介绍,与TPU v4相比,TPU v5p的浮点运算性能提升了两倍,在高带宽内存方面提高了3倍。使用谷歌的600 GB/s芯片间互连,可以将8960个v5p加速器耦合在一个Pod(通常指一个包含多个芯片的集群或模块)中,从而更快或更高精度地训练模型。作为参考,该值比TPU v5e大35倍,是TPU v4的两倍多。
谷歌称,TPU v5p是其迄今为止最强大的,能够提供459 teraFLOPS(每秒可执行459万亿次浮点运算)的bfloat16(16位浮点数格式)性能或918 teraOPS(每秒可执行918万亿次整数运算)的Int8(执行8位整数)性能,支持95GB的高带宽内存,能够以2.76 TB/s的速度传输数据。
谷歌表示,所有这些意味着TPU v5p可以比TPU v4更快地训练大型语言模型,如训练GPT-3(1750亿参数)这样的大语言模型速度比TPU v4快2.8倍。
不过,这种更高的性能和可扩展性也是有代价的。每个TPU v5p加速器的运行费用为每小时4.2美元,而TPU v4加速器为每小时3.22美元,TPU v5e加速器每小时1.2美元。
“在我们的早期使用阶段,谷歌DeepMind和谷歌Research观察到,与我们的TPU v4芯片相比,使用TPU v5p芯片的大语言模型(LLM)训练工作负载的速度提高了两倍。”谷歌DeepMind首席科学家杰夫·迪恩(Jeff Dean)写道,“对机器学习框架(JAX、PyTorch、TensorFlow)和编排工具的强大支持使我们能够在v5p上更高效地扩展。通过第二代SparseCores,我们还看到嵌入密集型工作负载的性能有了显着提高。TPU对于我们在Gemini等尖端模型上进行最大规模的研究和工程工作至关重要。”
除了新硬件之外,谷歌还引入了“人工智能超级计算机”的概念。谷歌云将其描述为一种超级计算架构,包括一个集成系统,具有开放软件、性能优化硬件、机器学习框架和灵活的消费模型。
谷歌计算和机器学习基础设施部门副总裁马克·洛迈尔(Mark Lohmeyer)在博客文章中解释道,“传统方法通常通过零碎的组件级增强来解决要求苛刻的人工智能工作负载,这可能会导致效率低下和瓶颈。”“相比之下,人工智能超级计算机采用系统级协同设计来提高人工智能训练、调整和服务的效率和生产力。”这可以理解为,与单独看待每个部分相比,这种合并将提高生产力和效率。换句话说,超级计算机是一个系统,其中任何可能导致性能低下的变量(硬件或软件)都受到控制和优化。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。